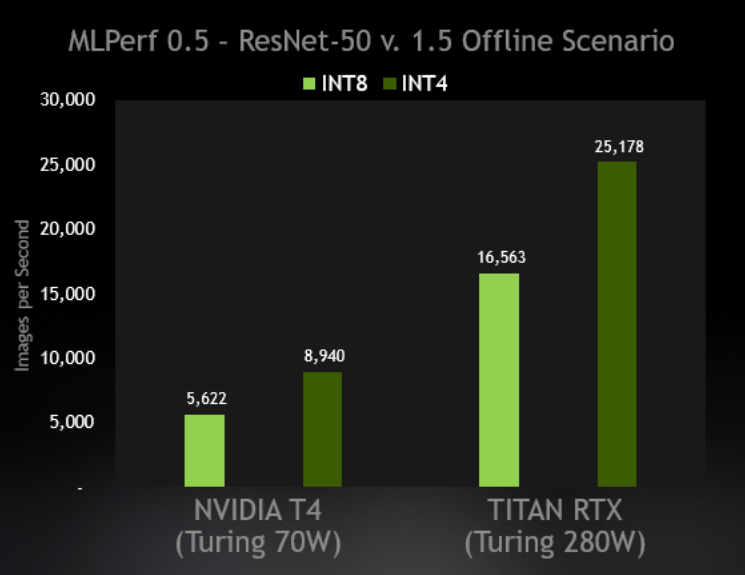
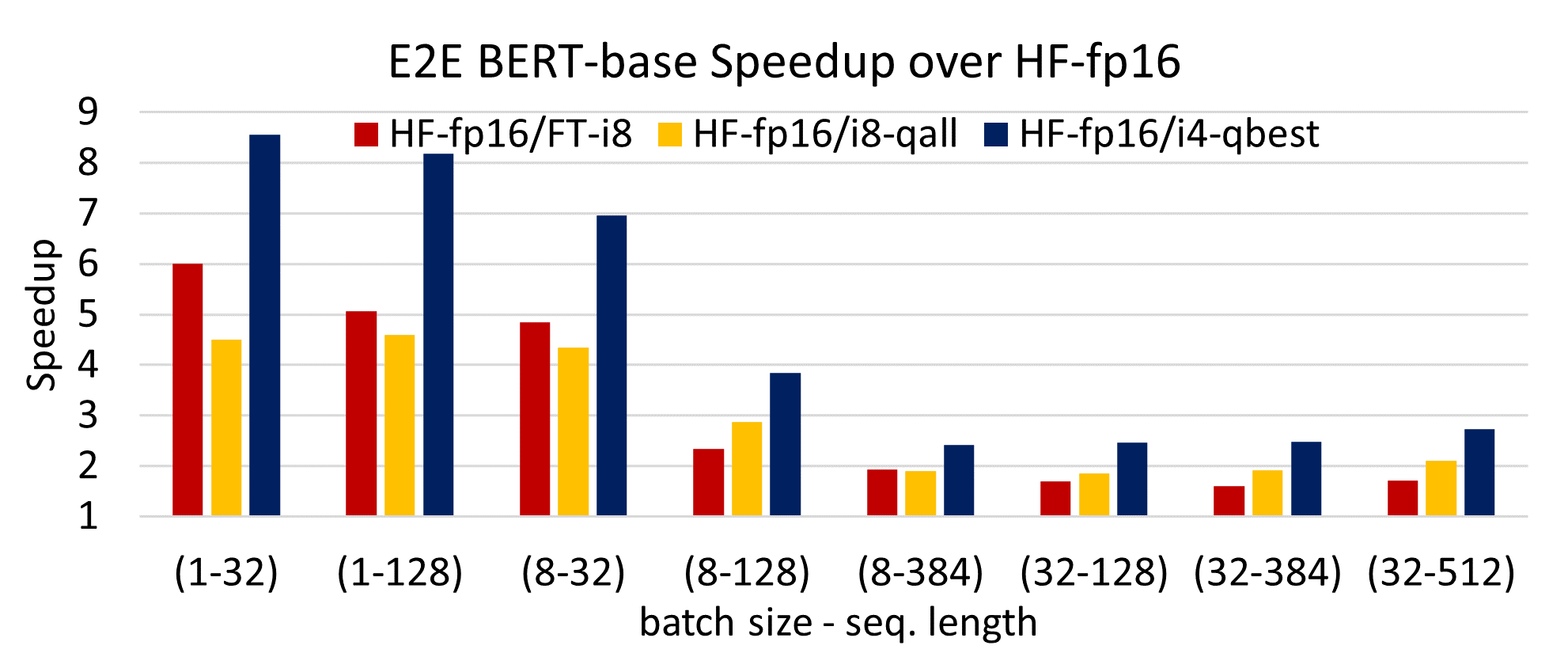
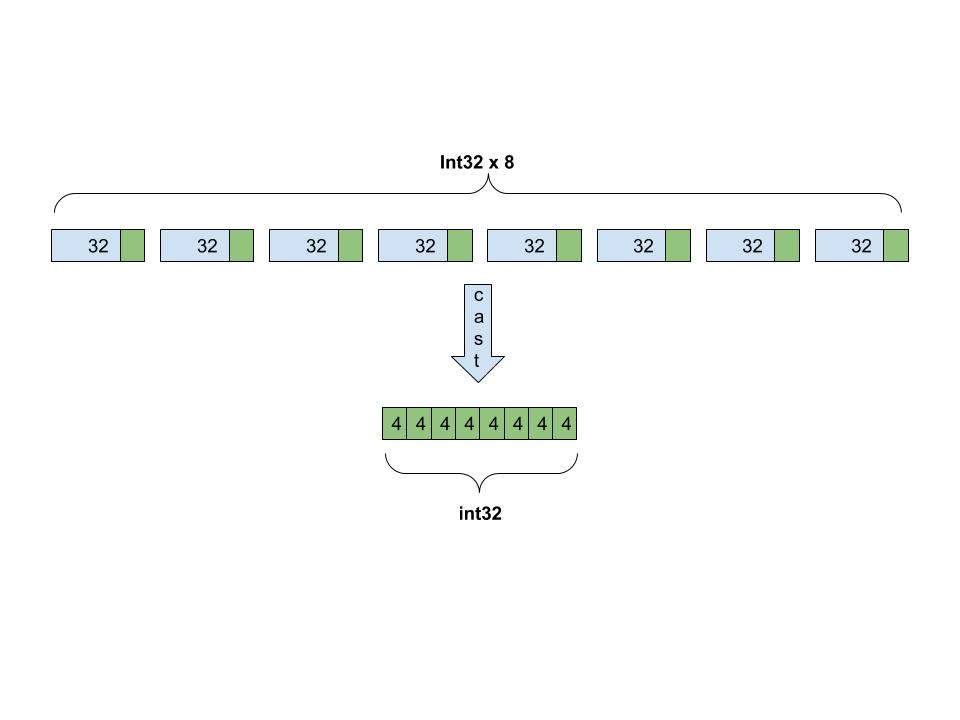
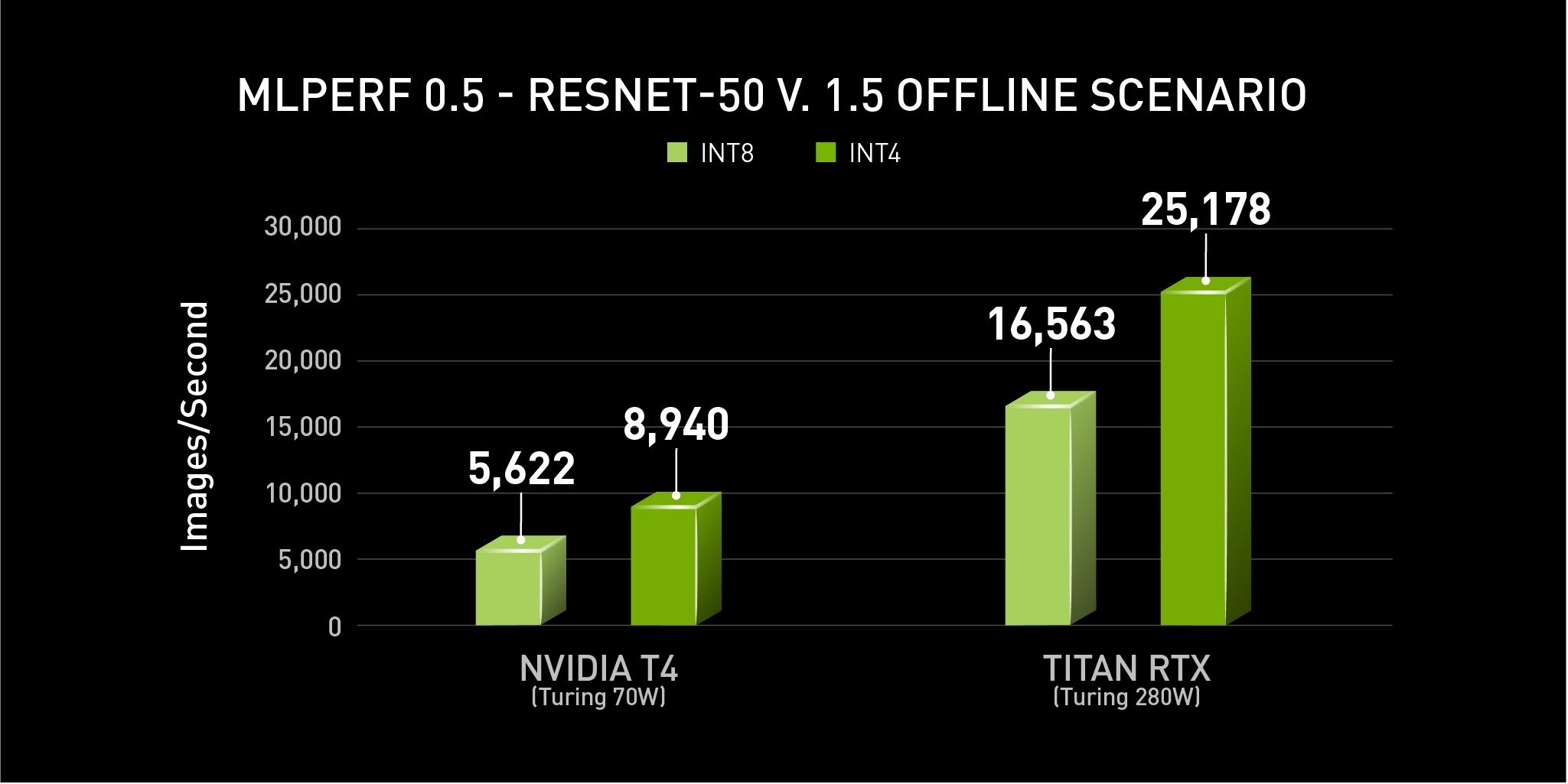
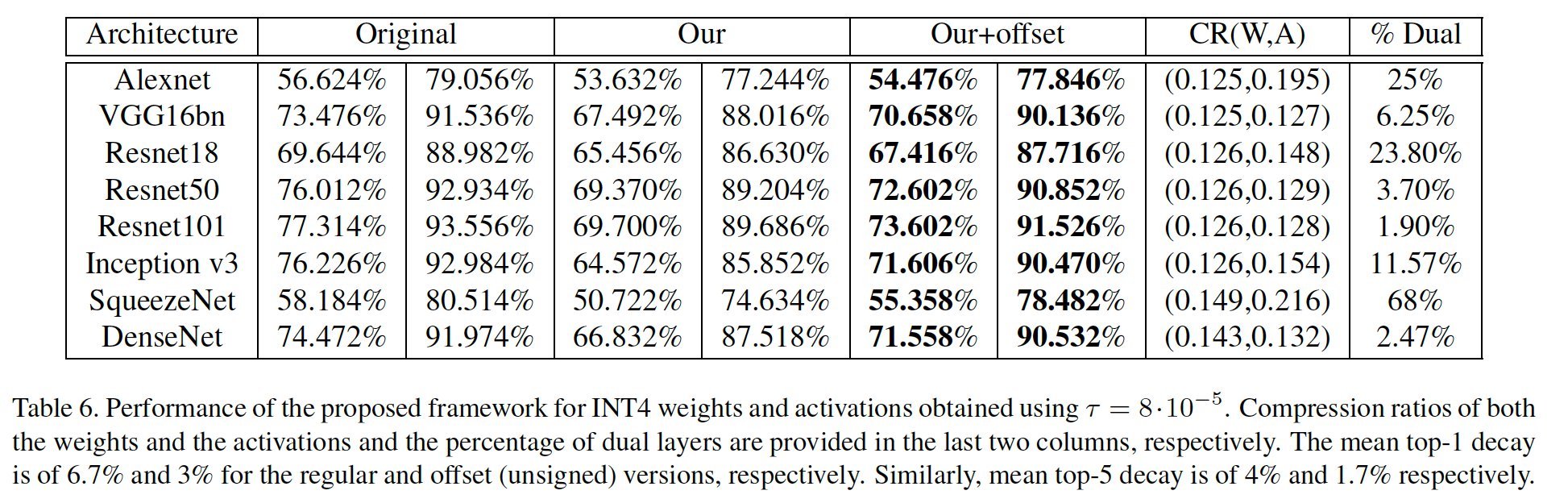
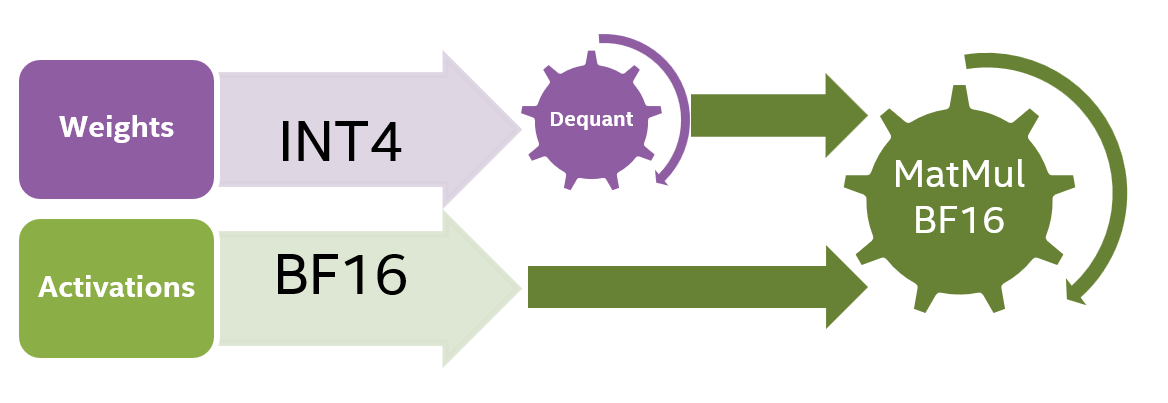
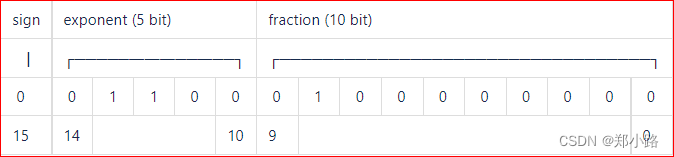
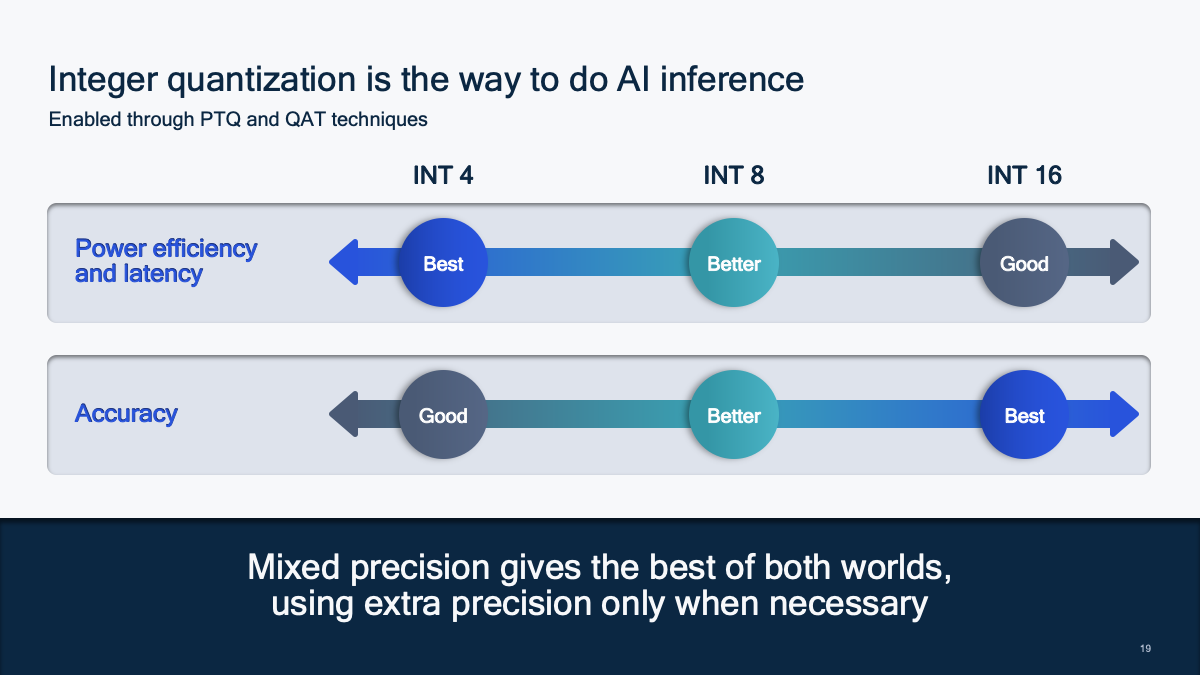
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
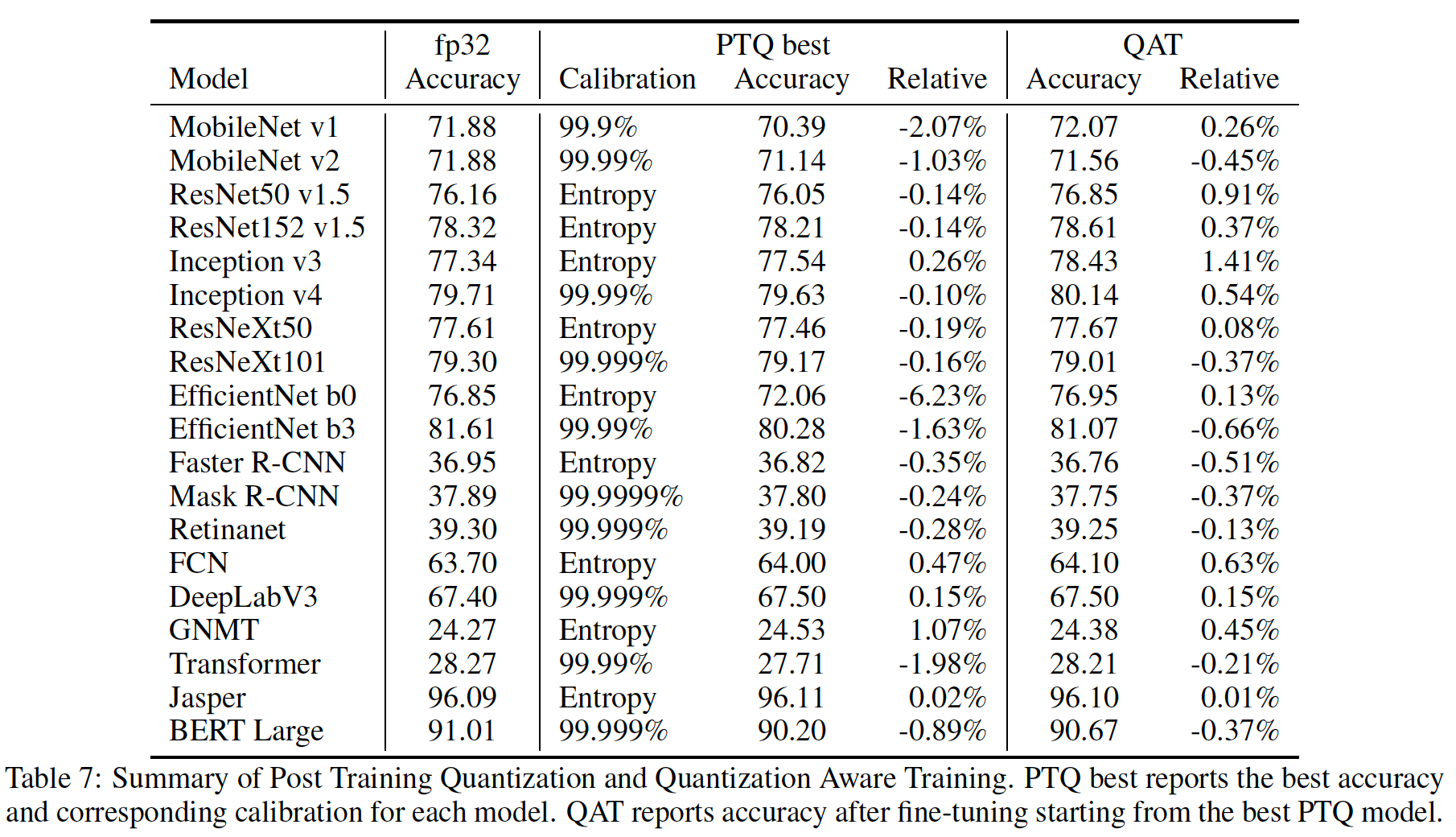
CUTLASS INT4 vs. INT8 GEMM performance comparison across different ...
int4 vs int8 vs uuid vs numeric performance on bigger joins
INT8 and INT4 Quantization ValueError · Issue #35 · moojink/openvla-oft ...
microsoft/Phi-3.5-mini-instruct-onnx · DirectML INT4 and INT8 AWQ model ...
面试官:为什么需要量化,为什么 int4 / int8 量化后大模型仍能保持性能? - 知乎
Could you upload the INT4 quantization and INT8 quantization model to ...
GPU Memory Is the New Budget. A practical guide to FP8, INT8, INT4 ...
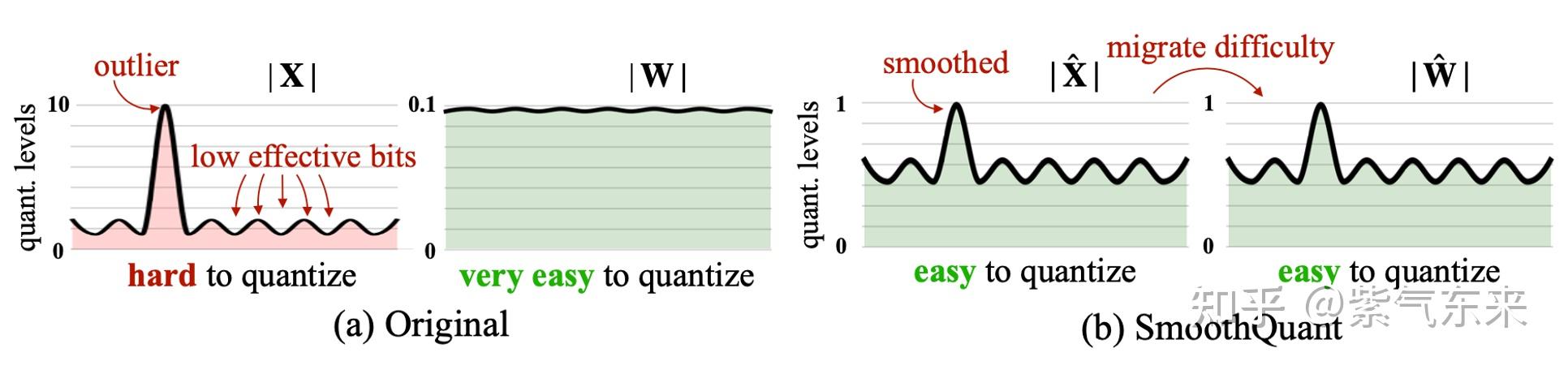
LLM 推理量化评估:FP8、INT8 与 INT4 的全面对比 - 知乎
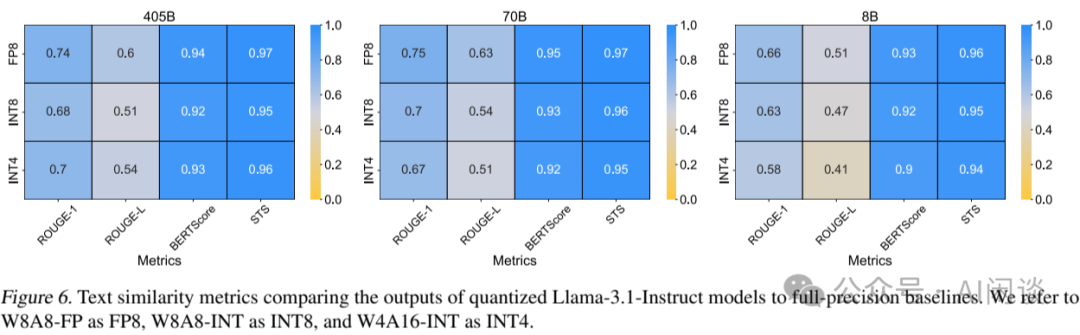
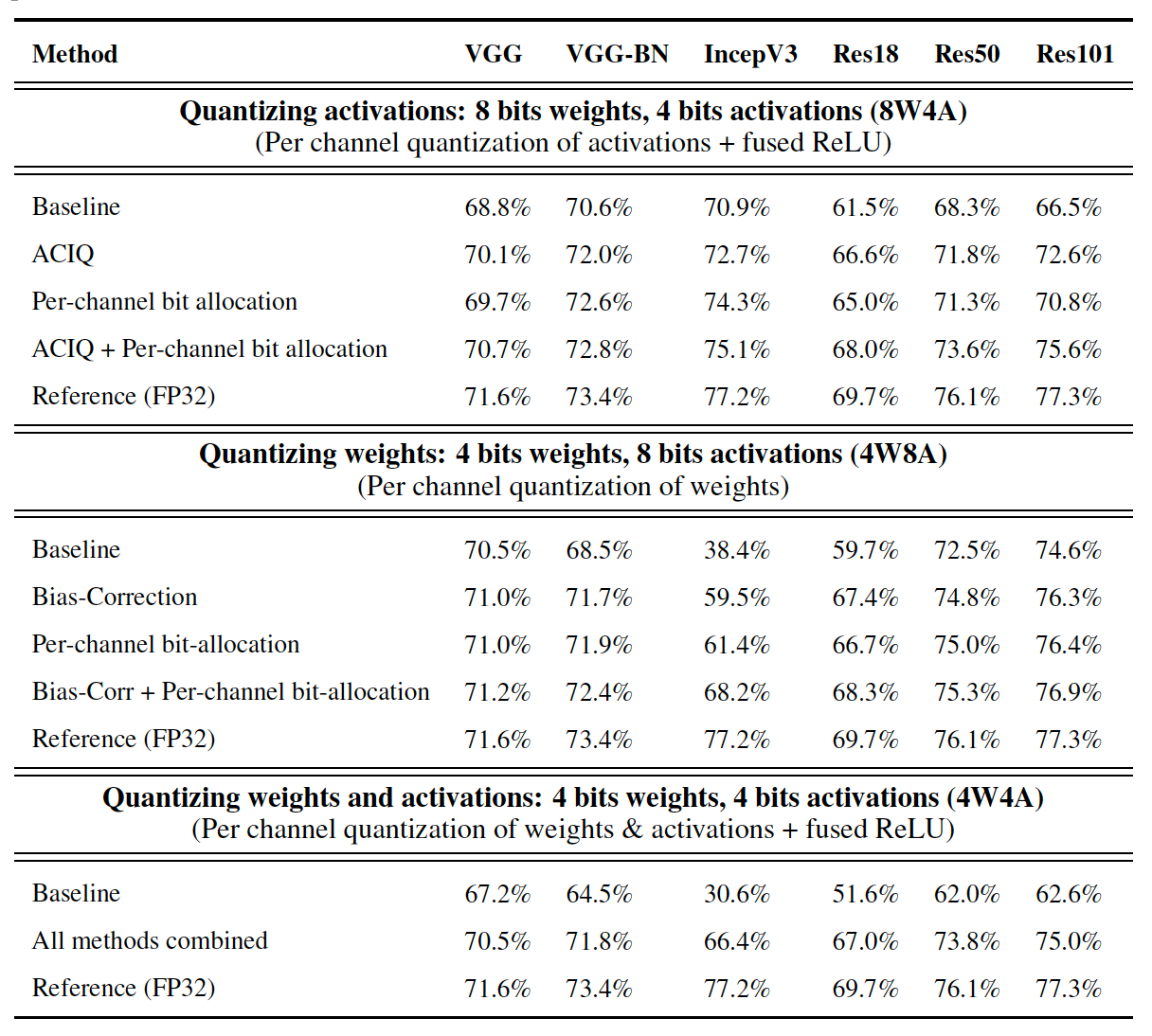
[2301.12017] Understanding INT4 Quantization for Language Models ...
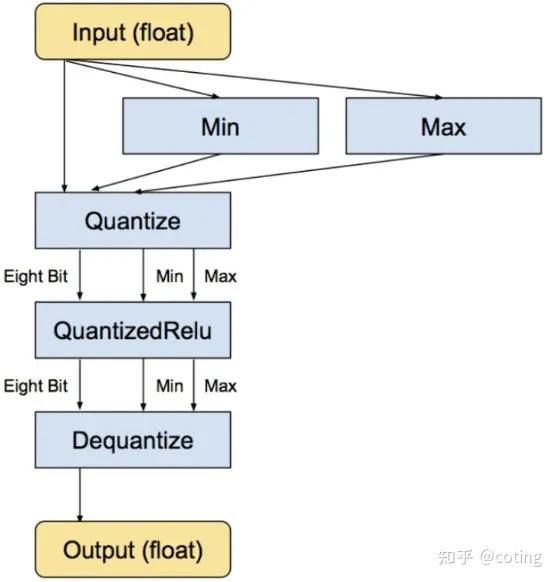
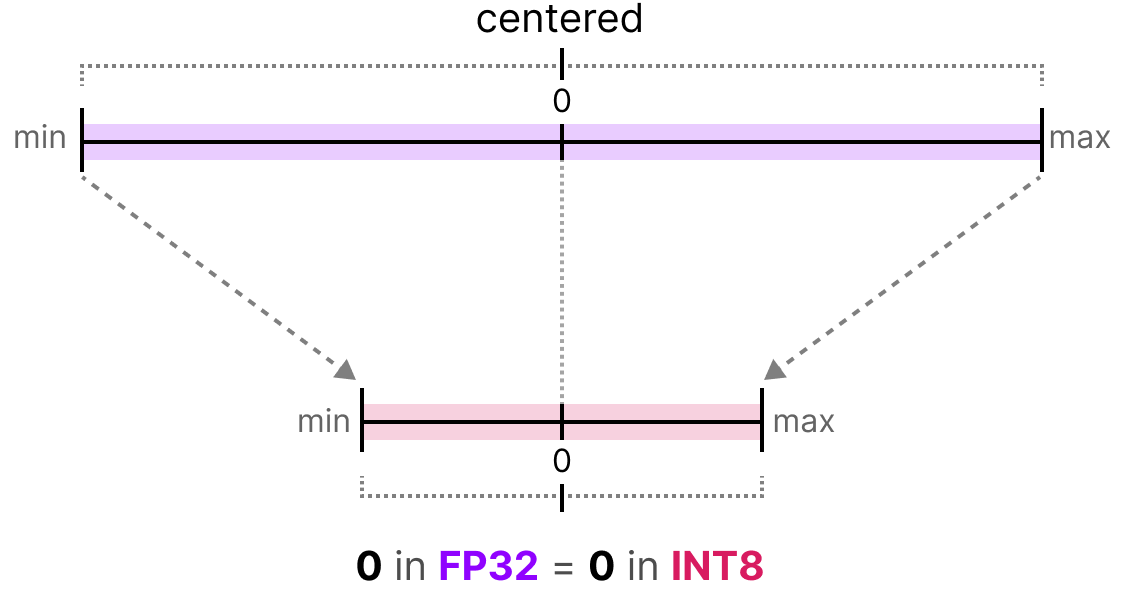
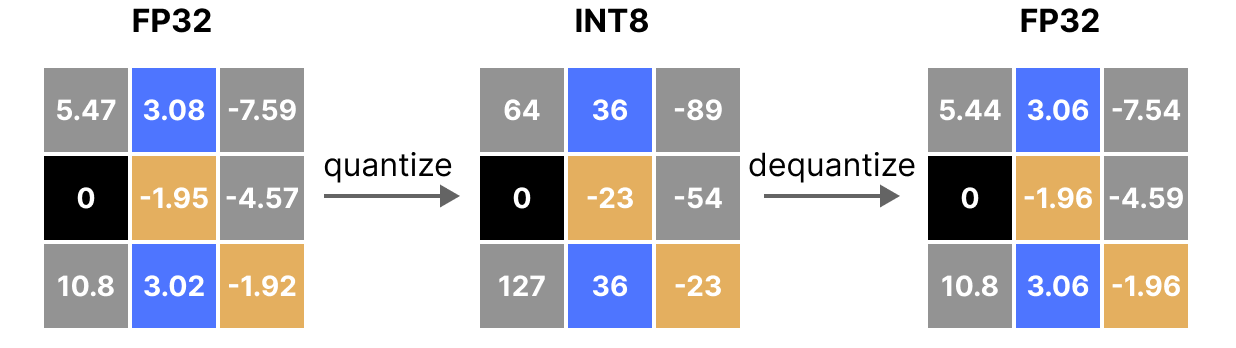
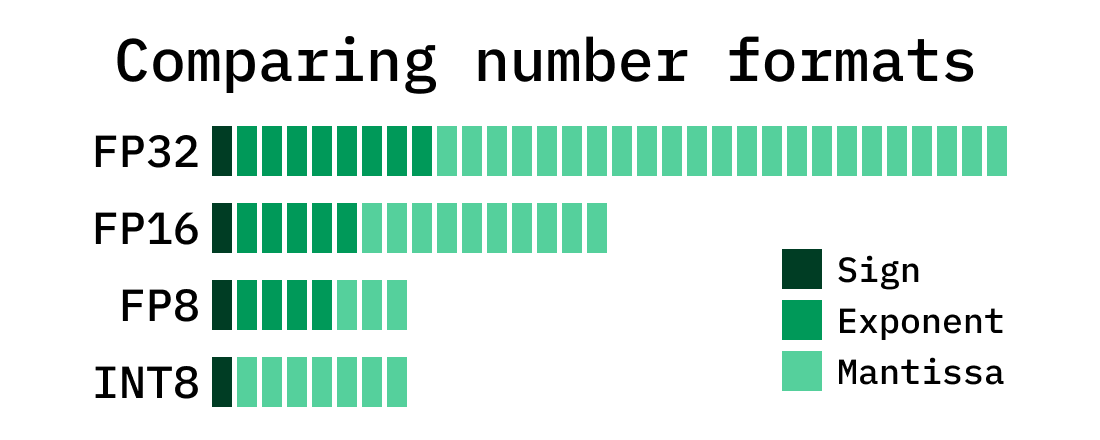
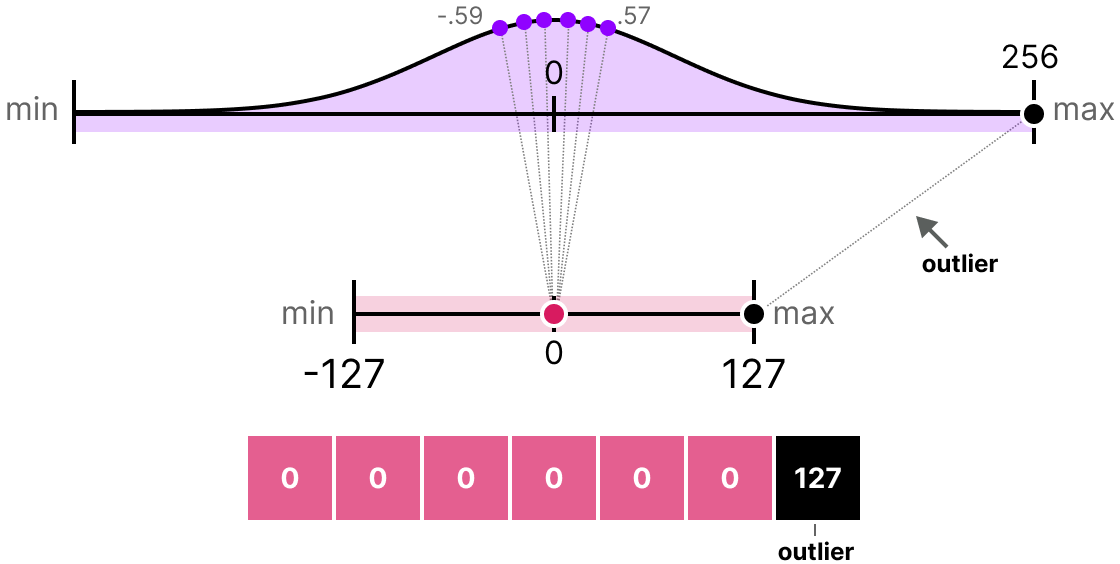
INT8, INT4 and Other Integer Types for Quantization
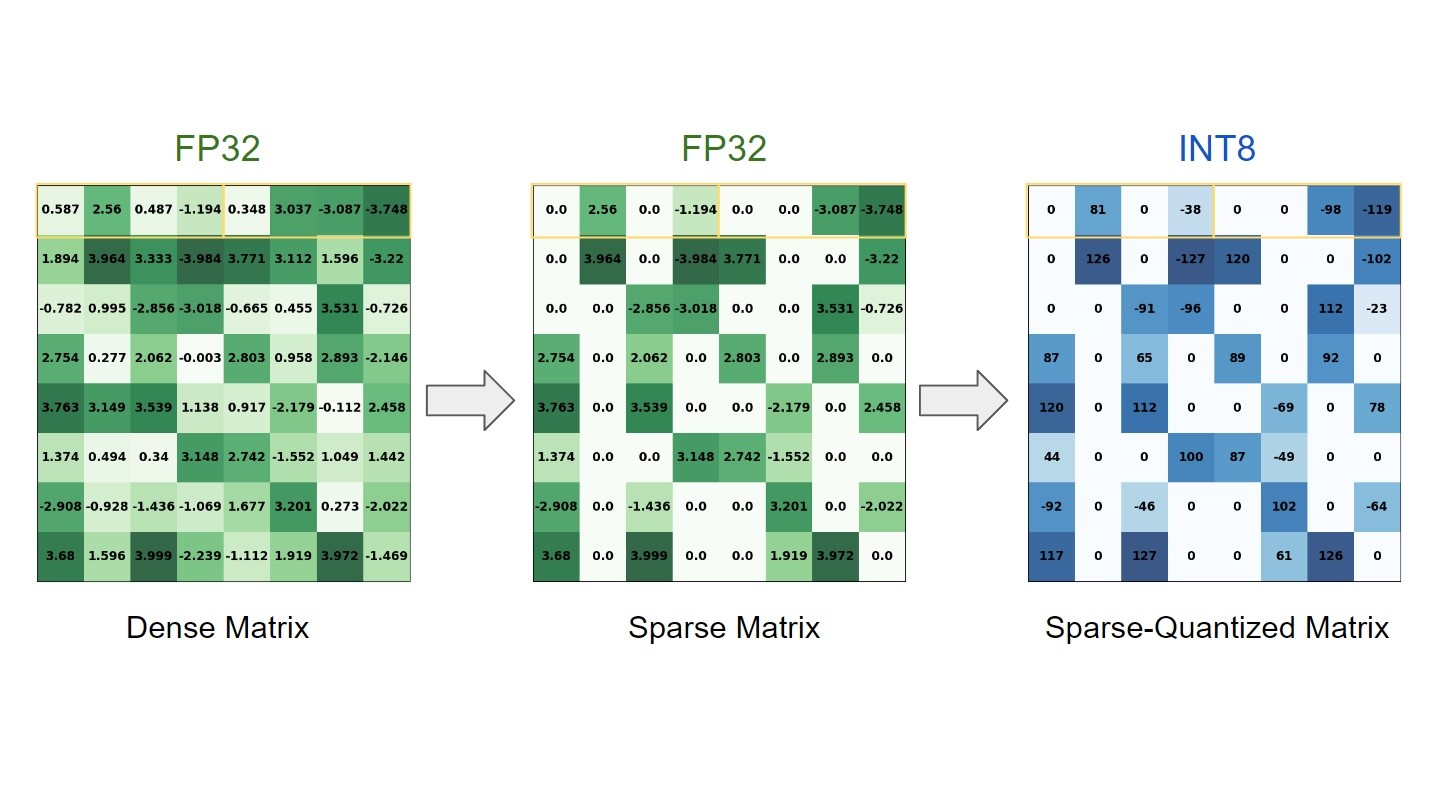
INT8 中的稀疏性:NVIDIA TensorRT 加速的训练工作流程和最佳实践 - 知乎
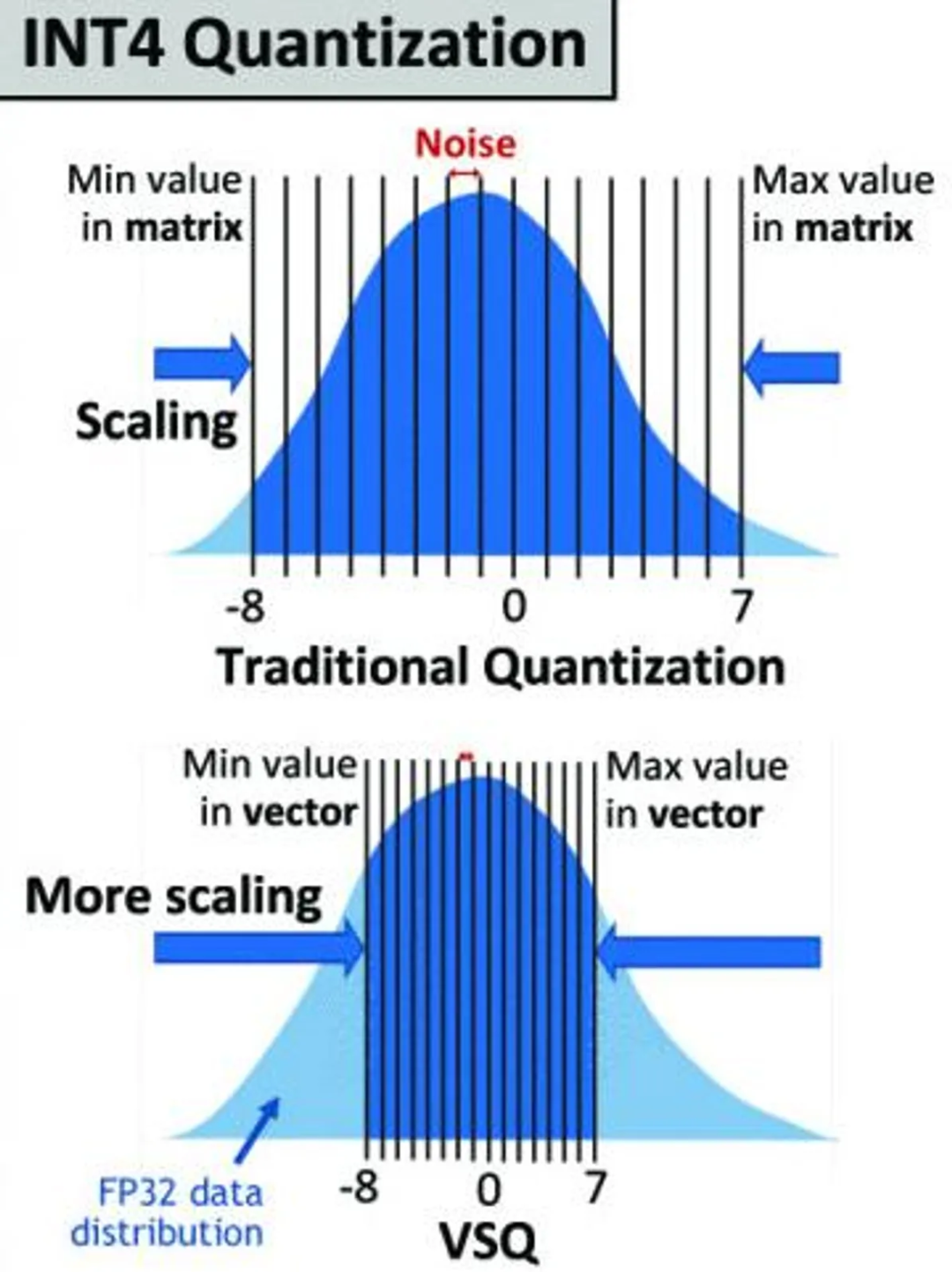
Int4 Precision for AI Inference | NVIDIA Technical Blog
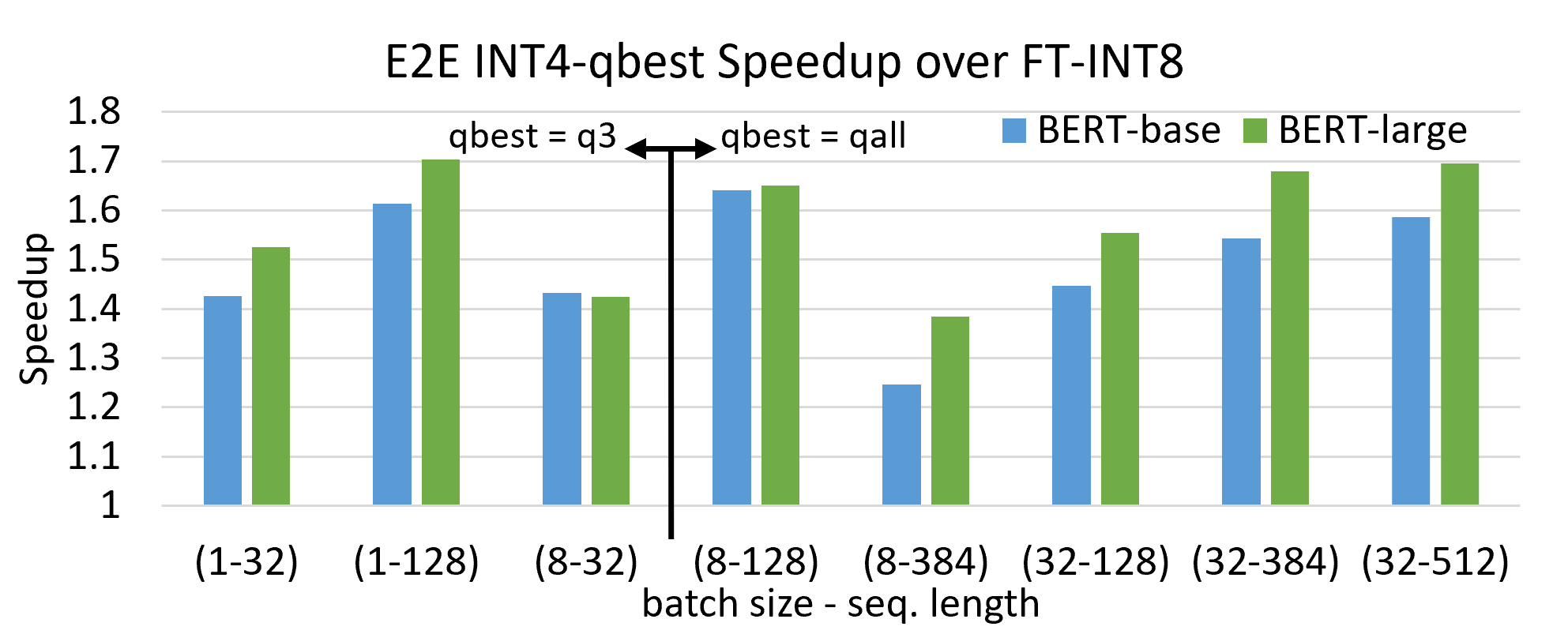
[RFC][Tensorcore] INT4 end-to-end inference - pre-RFC - Apache TVM Discuss
Int4 Precision for AI Inference - Edge AI and Vision Alliance
[2303.17951] FP8 versus INT8 for efficient deep learning inference
LLM 推理量化评估:FP8、INT8 与 INT4 的全面对比_int4和fp8-CSDN博客
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
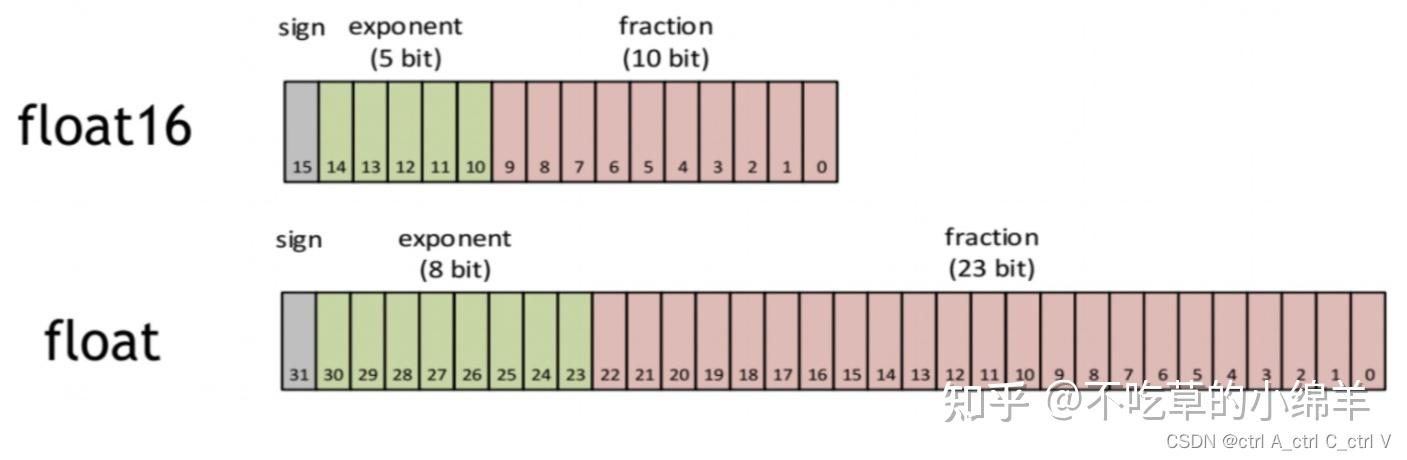
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
[QST] INT8 (and potentially INT4) Convolution Kernel with Additional ...
Support float8, int8, int4 in `diffusers`? · huggingface diffusers ...
Improve Inference with INT8 Quantization for x86 CPU in PyTorch
bf16, fp32, fp16, int8, int4 in LLM | by Jasminewu_yi | Medium
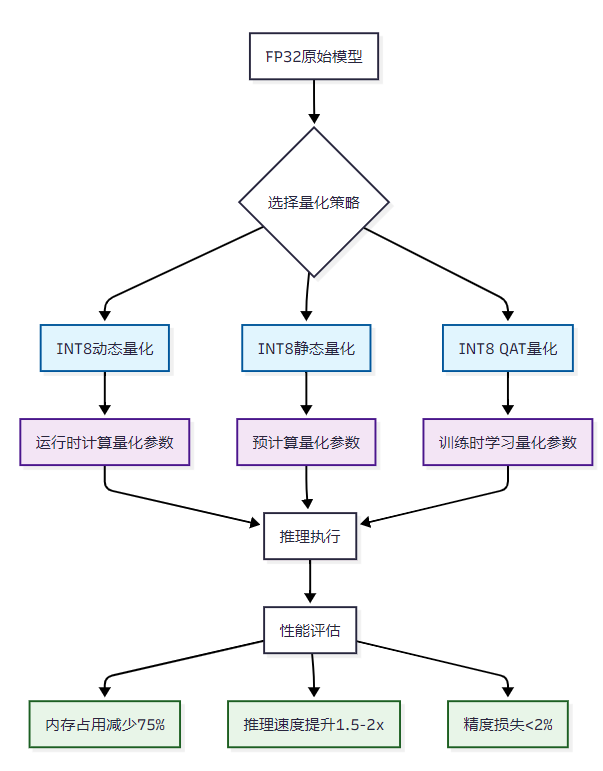
A Hands-On Walkthrough on Model Quantization - Medoid AI
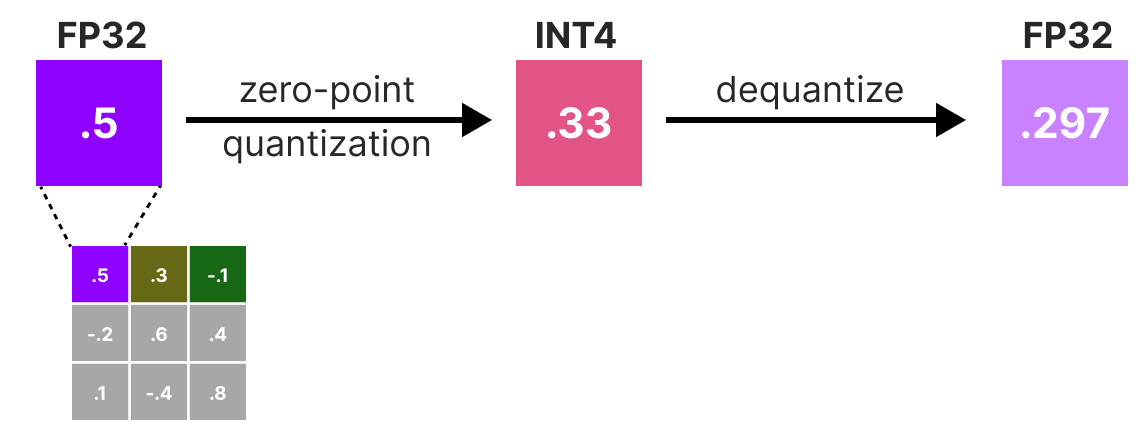
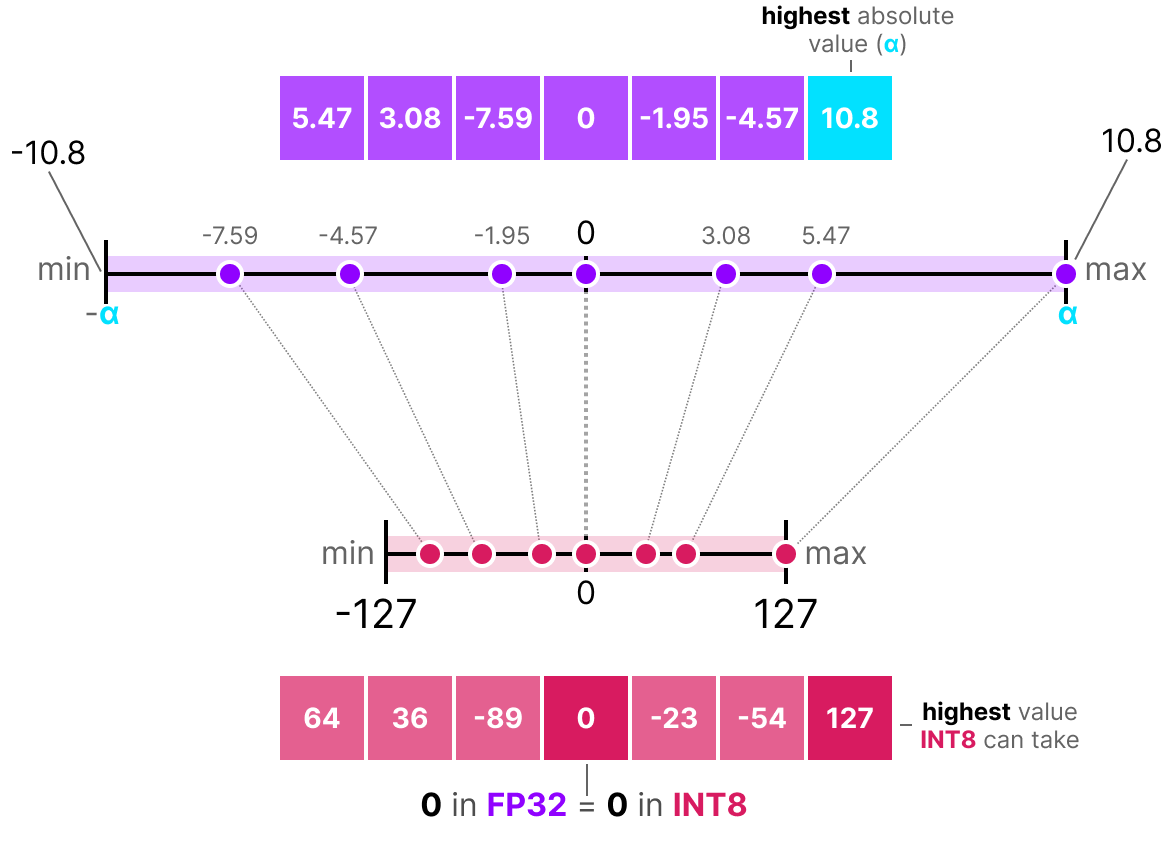
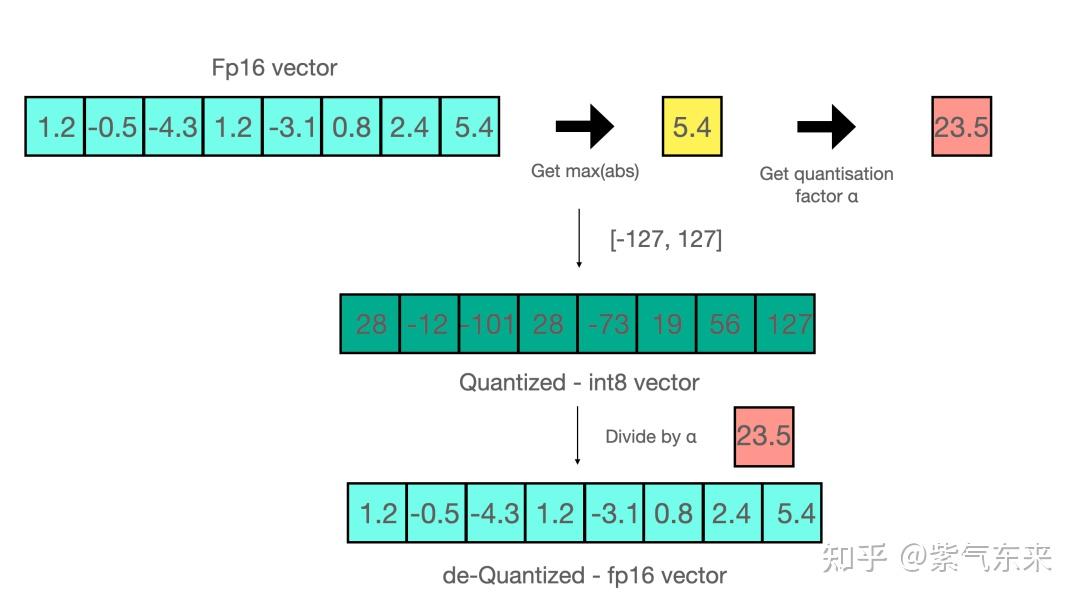
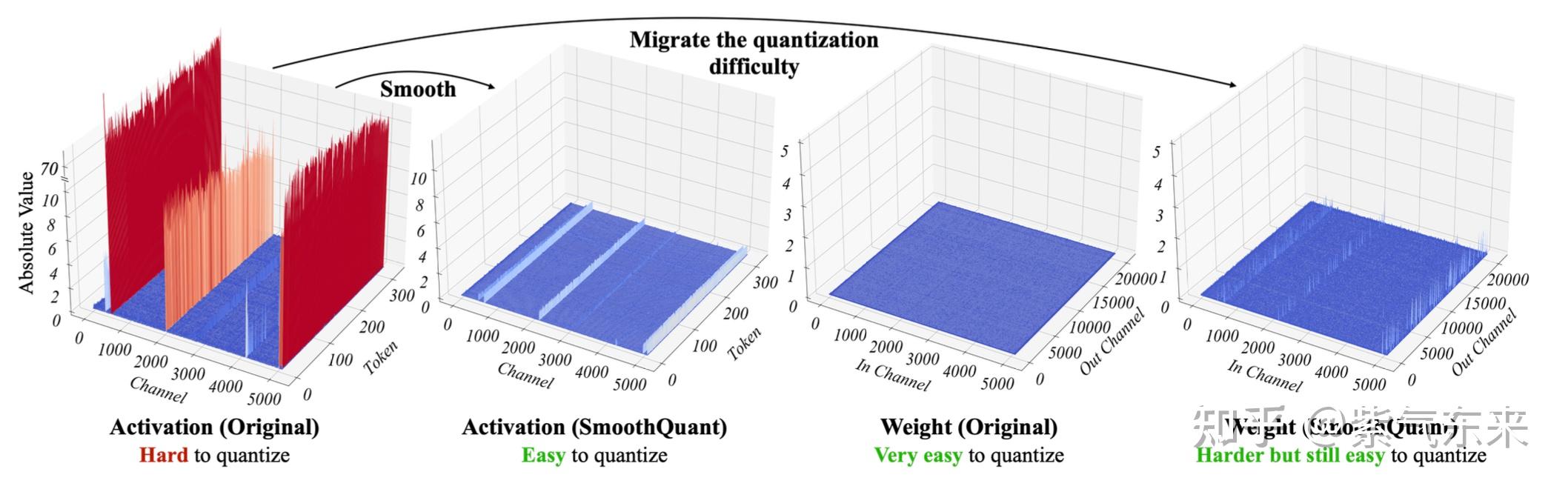
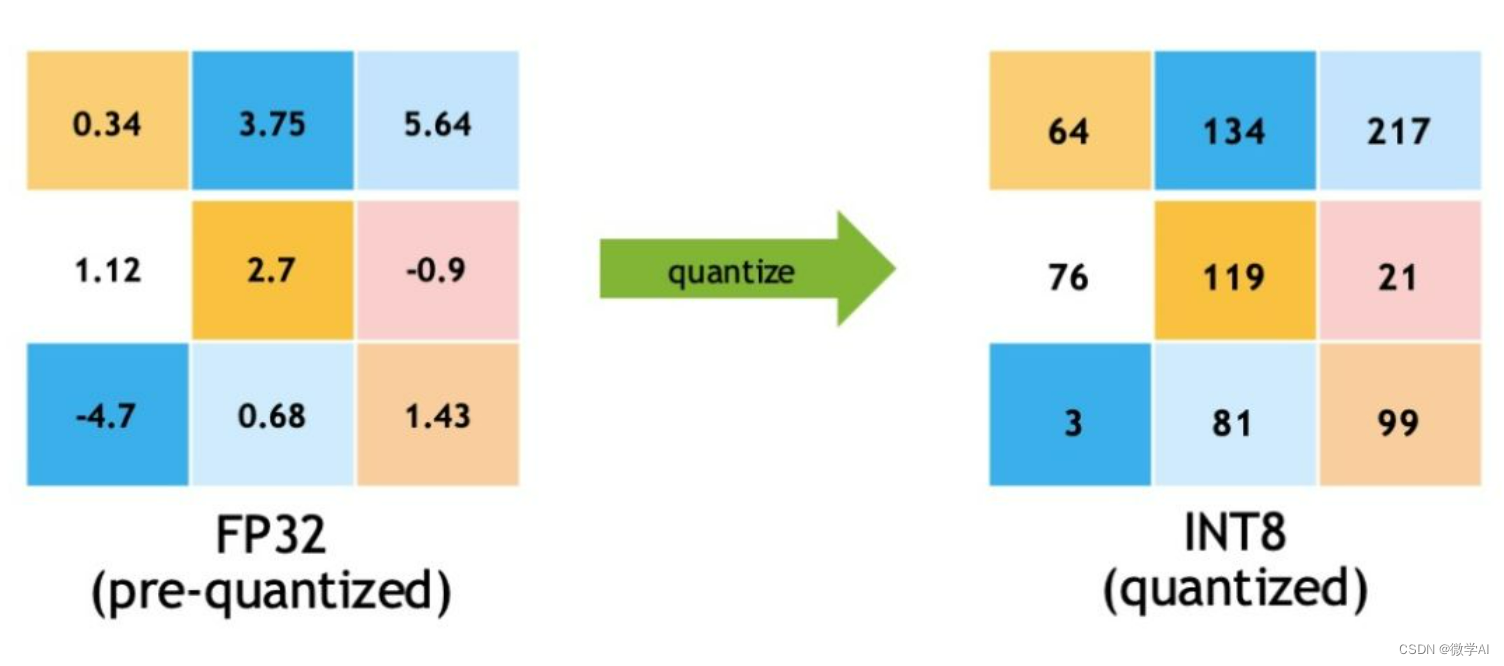
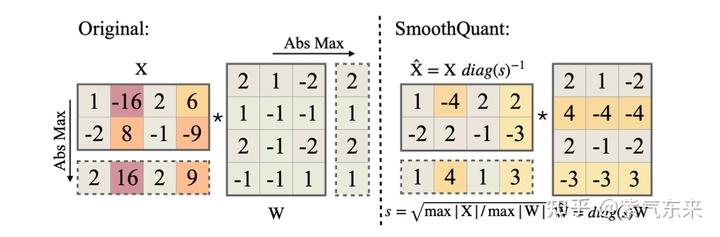
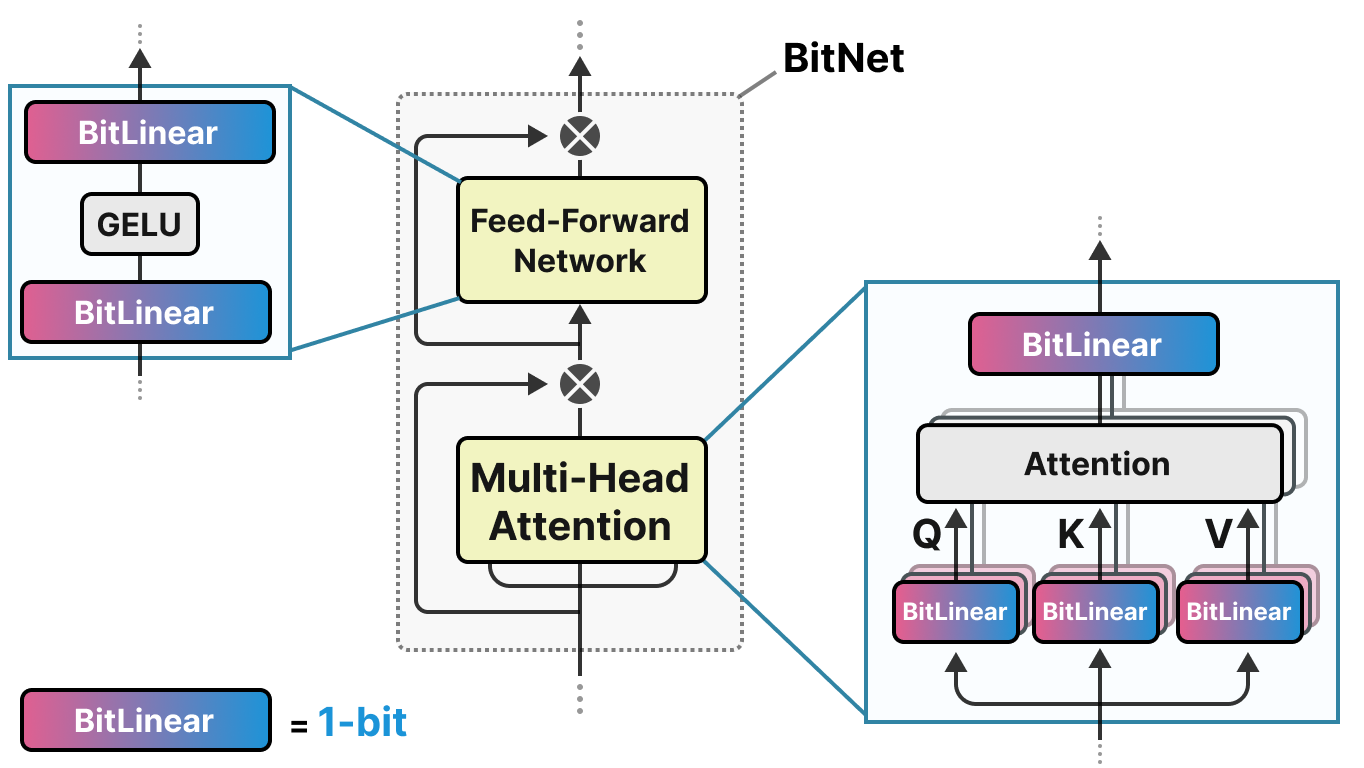
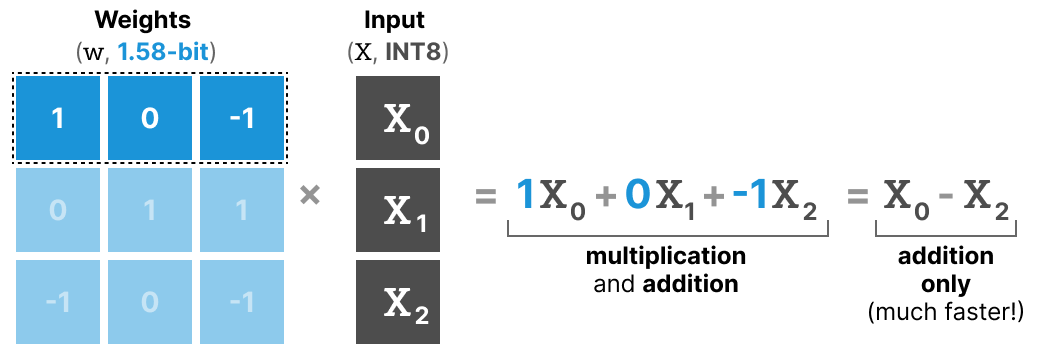
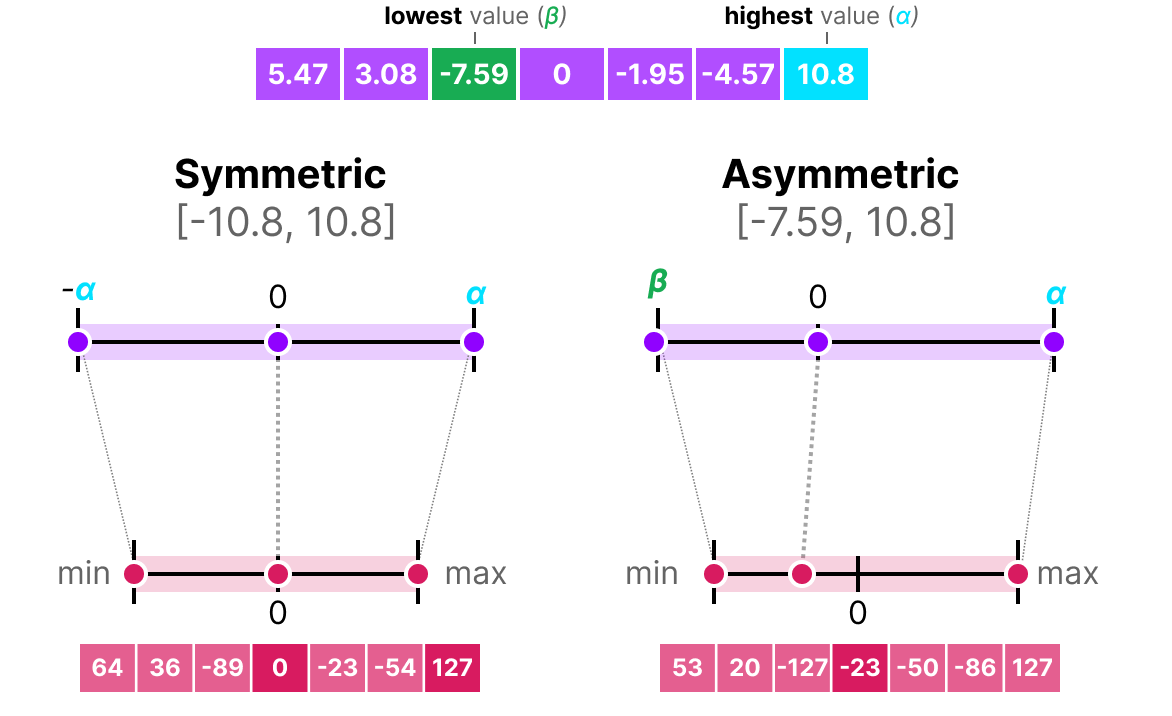
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度_风闻
小白也能懂!INT4、INT8、FP8、FP16、FP32量化-CSDN博客
大语言模型的模型量化(INT8/INT4)技术-CSDN博客
【科普】大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析 - 墨天轮
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度,每瓦运算速度可达H100的十倍 - 知乎
TensorRT INT8量化原理与实现(非常详细)-CSDN博客
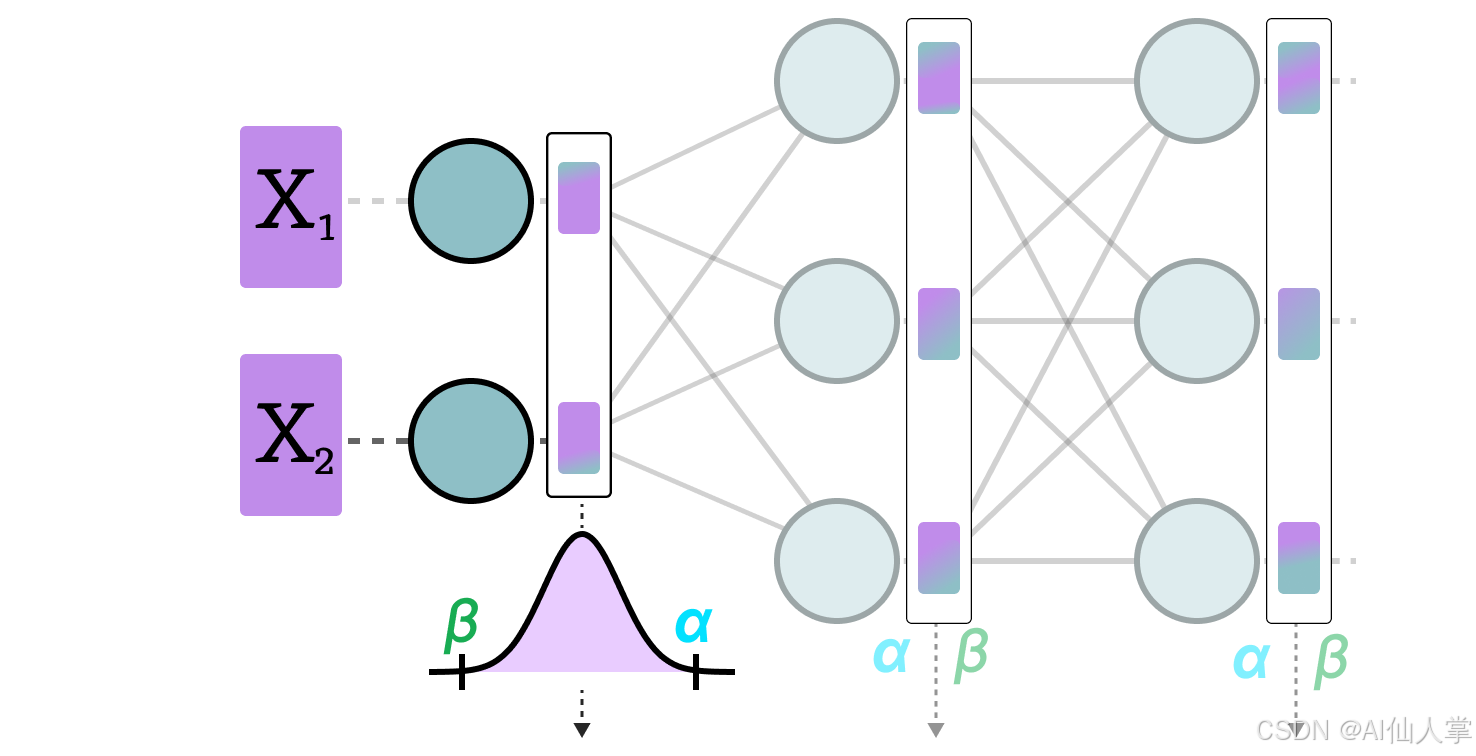
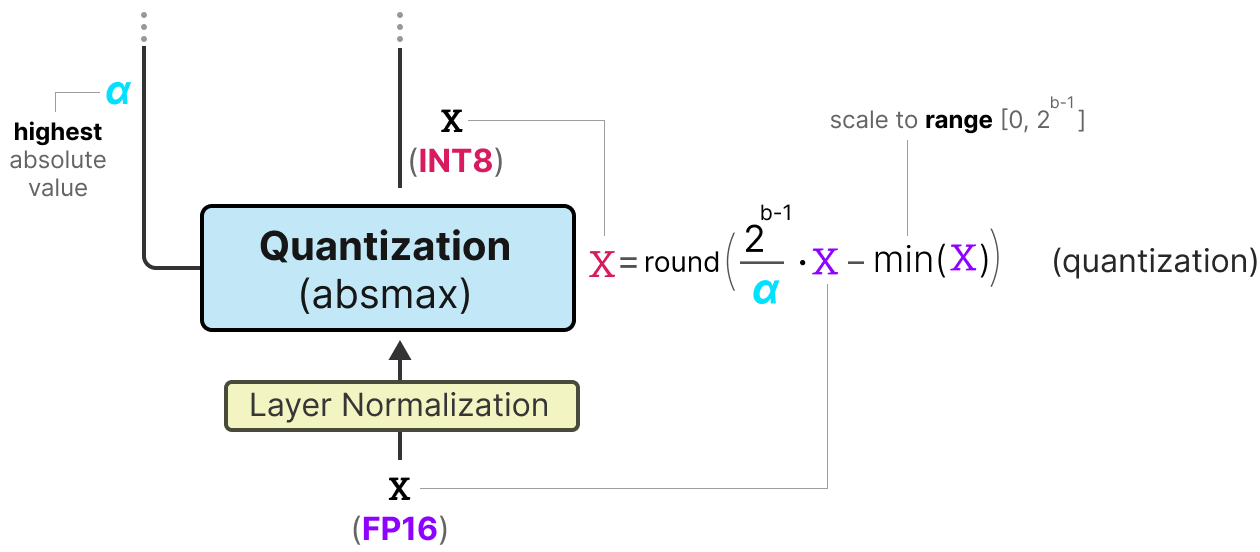
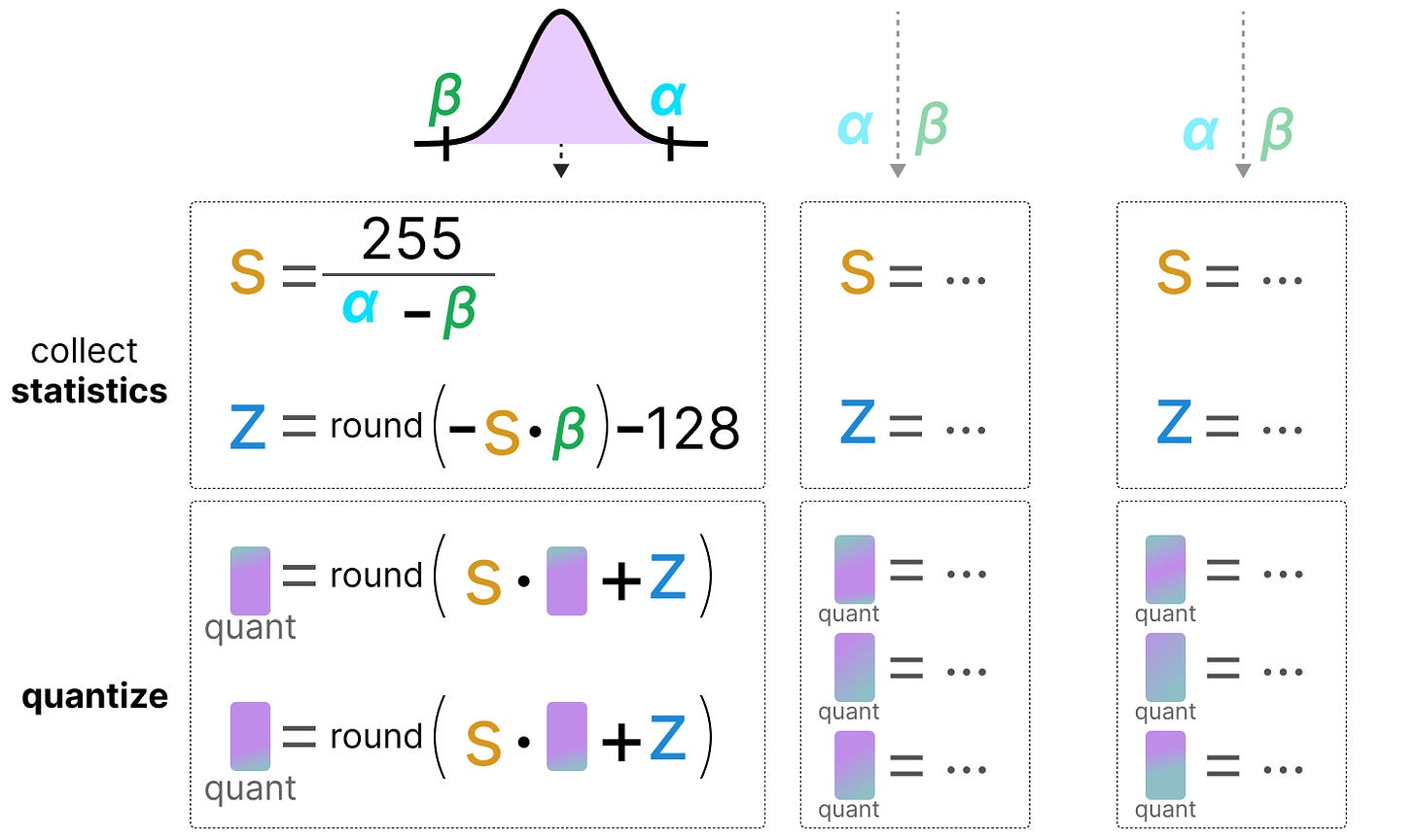
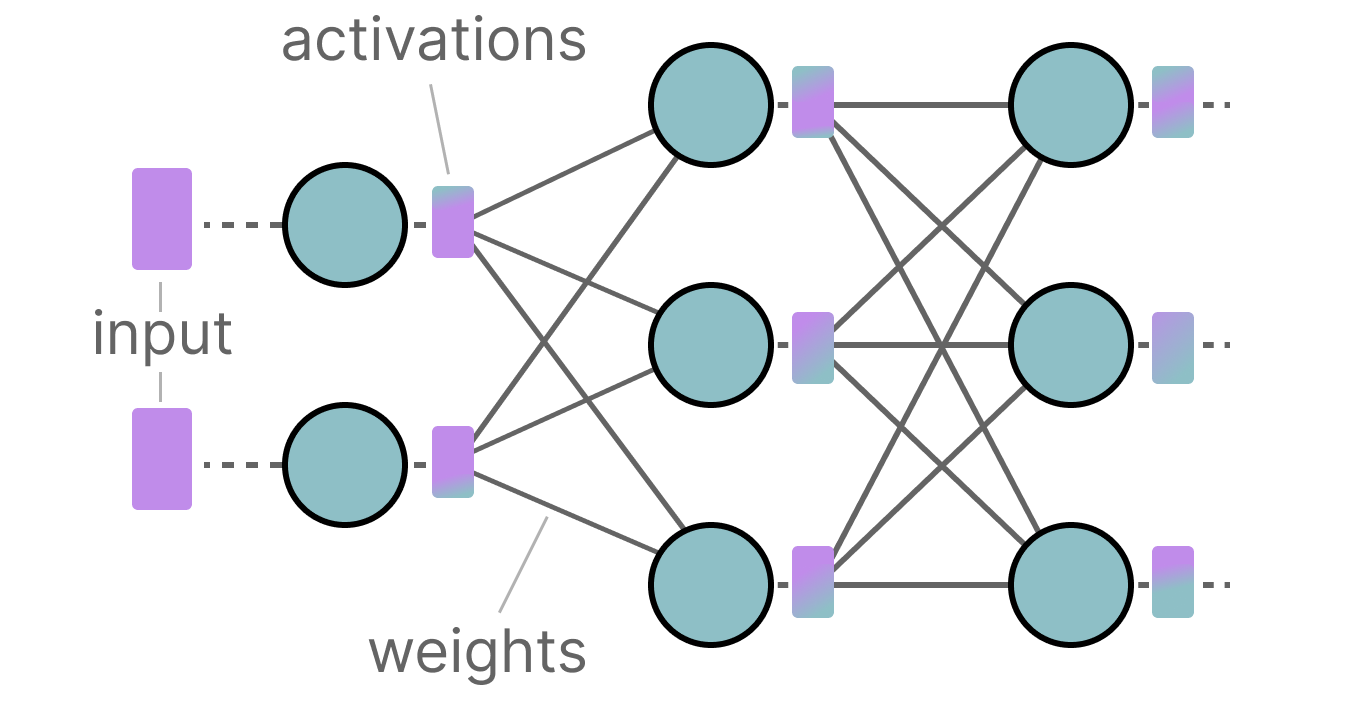
用于量化的INT8、INT4及其他整数类型
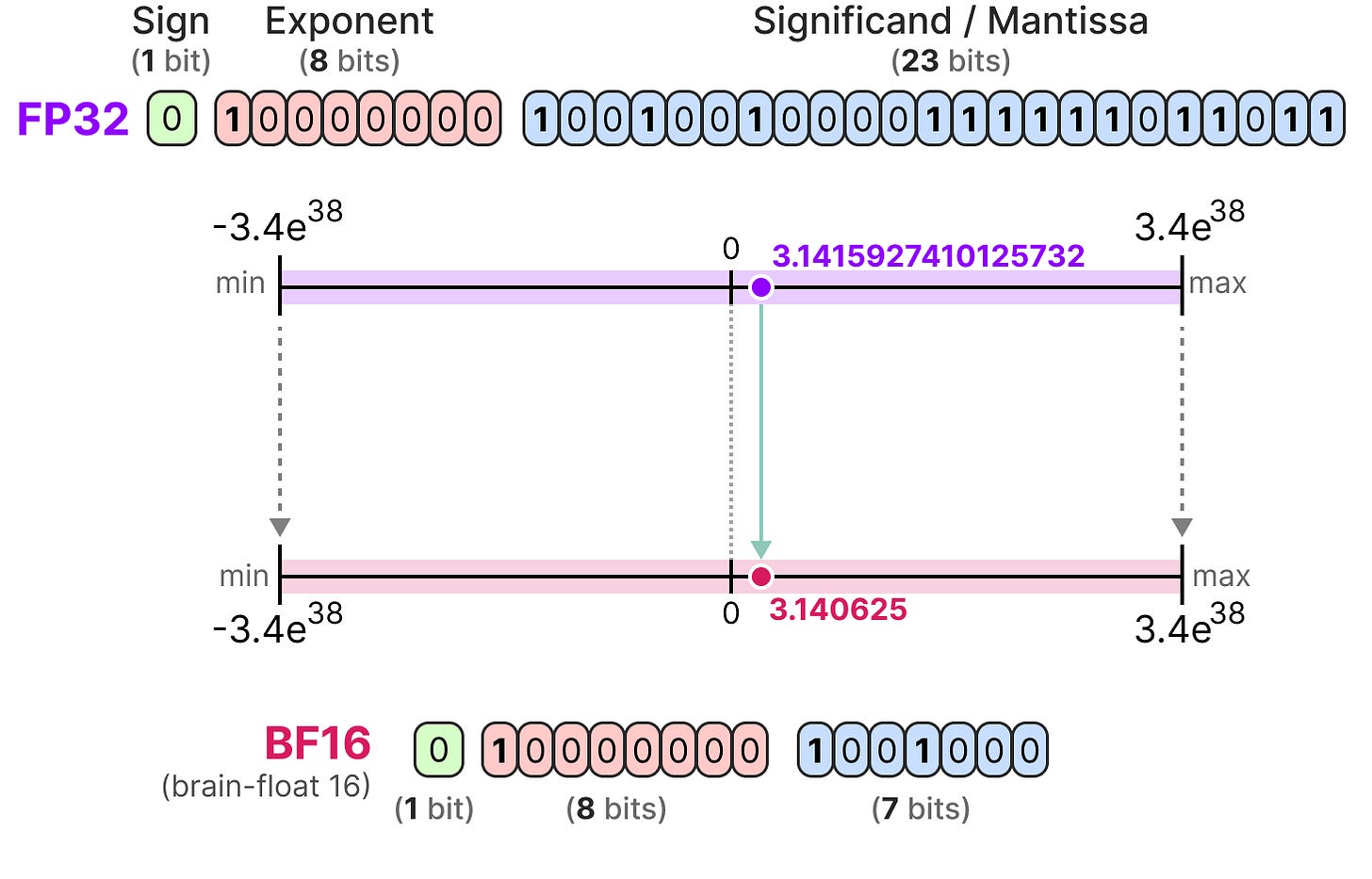
Understanding data types
大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析_顺其自然~-MCP技术社区
转载:【AI系统】低比特量化原理 - Khronos6 - 博客园
模型量化大揭秘:INT8、INT4量化对推理速度和精度的影响测试 - 技术栈
pytorch/SmolLM3-3B-INT8-INT4 · Hugging Face
LLM(十一):大语言模型的模型量化(INT8/INT4)技术 - 知乎
Quantization from FP32 to INT8. | Download Scientific Diagram
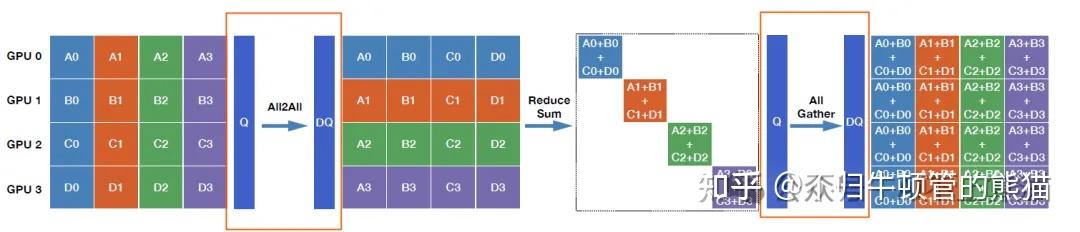
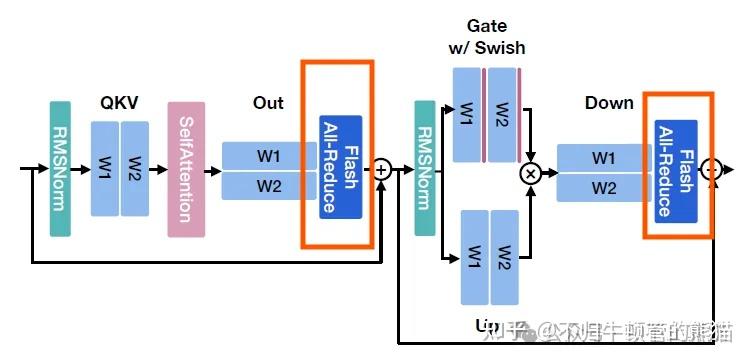
大模型通信算子--int8/int4 custom AllReduce kernel的动机、挑战和设计 - 知乎
A Practical Guide to LLM Quantization (int8/int4) | Hivenet
小白也能懂!INT4、INT8、FP8、FP16、FP32量化_独钓渔的技术博客_51CTO博客
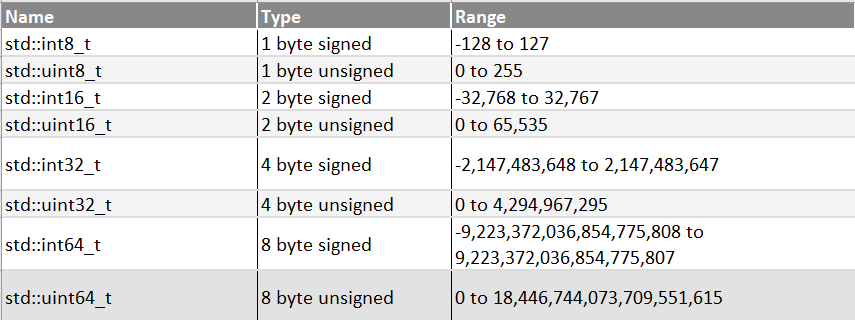
iOS 和 swift 中常见的 Int、Int8、Int16、Int32和 Int64介绍「建议收藏」-腾讯云开发者社区-腾讯云
模型量化(int8)系统知识导读_int4量化-CSDN博客
mysql - Difference between "int" and "int(2)" data types - Stack Overflow
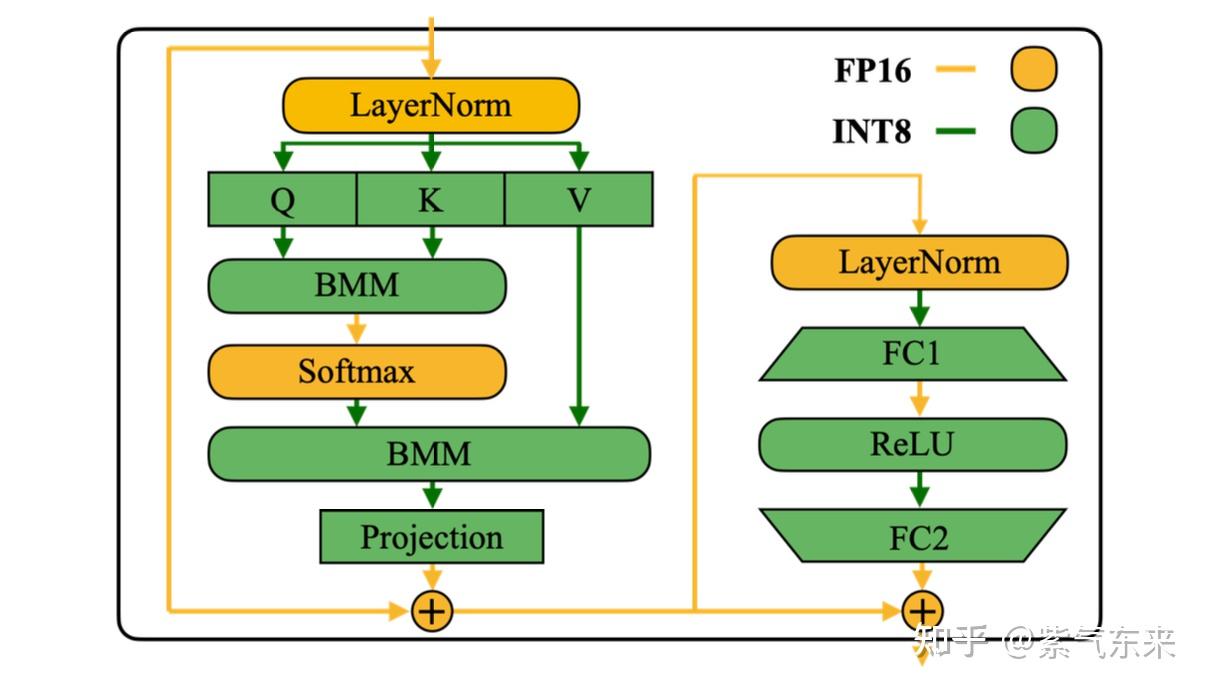
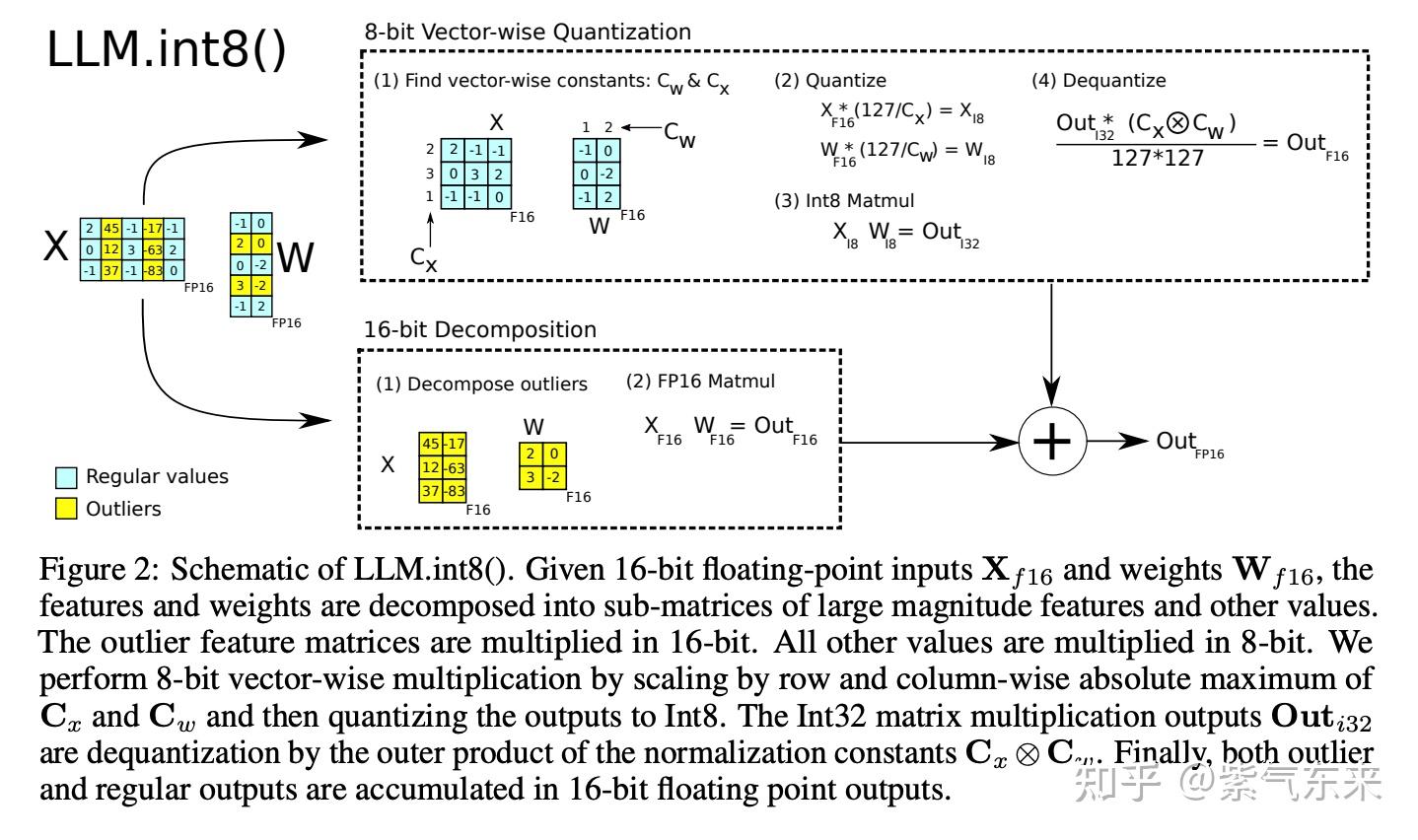
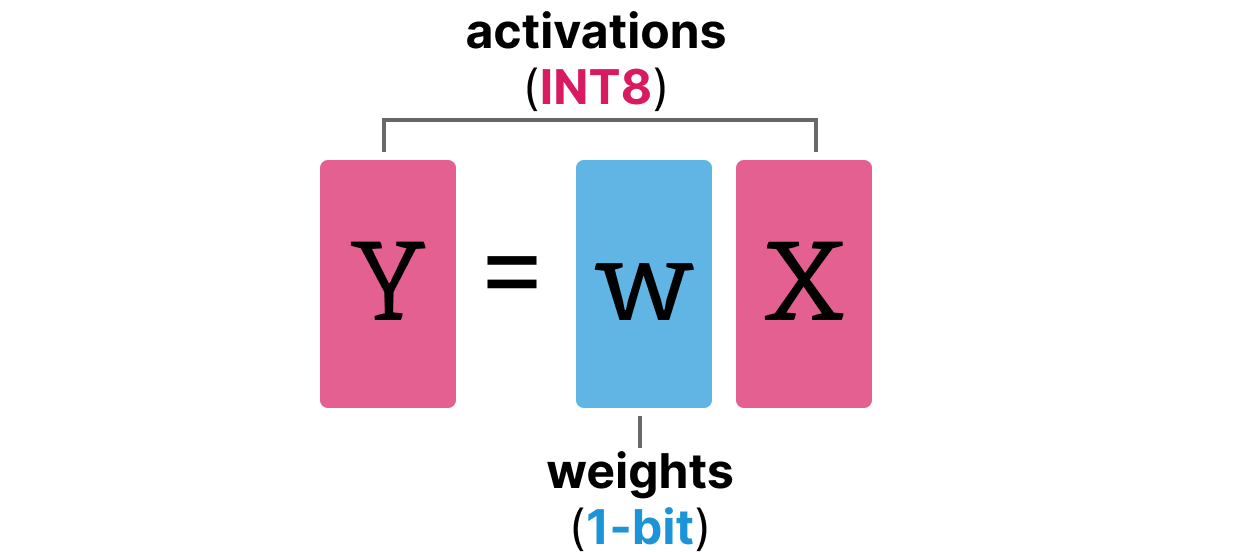
大模型 LLM.int8() 量化技术原理与代码实现-51CTO.COM
神经网络INT8量化~部署_tensorrt树莓派-CSDN博客
NVIDIA GPU 架构下的 FP8 训练与推理_汽车技术__汽车测试网
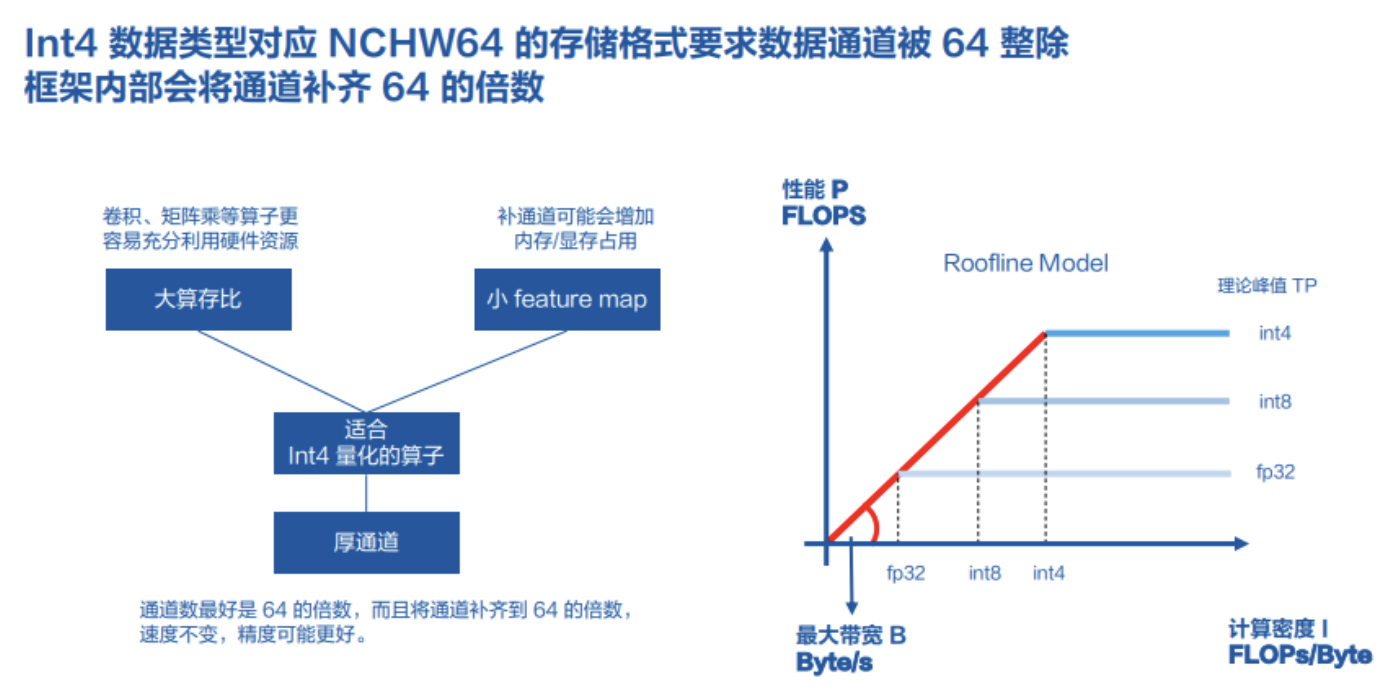
深度学习框架MegEngine CUDA INT4推理方案学习 - 极术社区 - 连接开发者与智能计算生态
骁龙AI进化论:推开新世界的大门
自动驾驶中神经网络模型量化技术:INT8还是INT4? - 知乎
机器学习中的新数学,加速AI训练离不开数字表示方式和基本计算的变革-腾讯云开发者社区-腾讯云
FP32, BF16,int8, int4的区别 - 知乎
TensorRT模型转换及部署,FP32/FP16/INT8精度区分_tensorrt engine in fp16-CSDN博客
FP16\FP32\INT8\混合精度的含义-CSDN博客
Unsigned Int Range CS 307
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
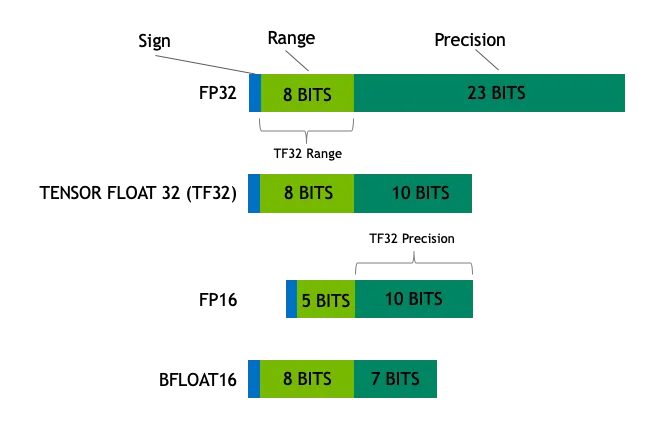
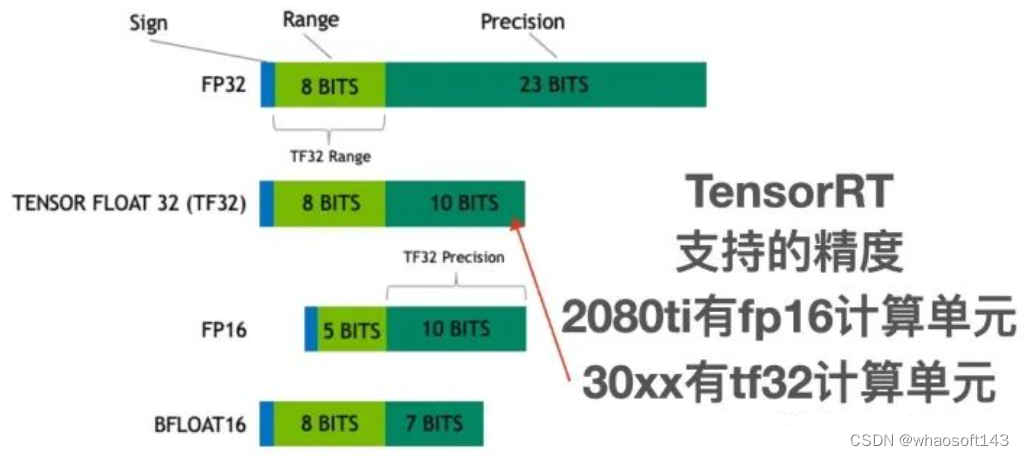
模型精度问题(FP16,FP32,TF32,INT8)精简版_fp32、fp16、int8、tf32-CSDN博客
Floating-point arithmetic for AI inference — hit or miss? | Qualcomm
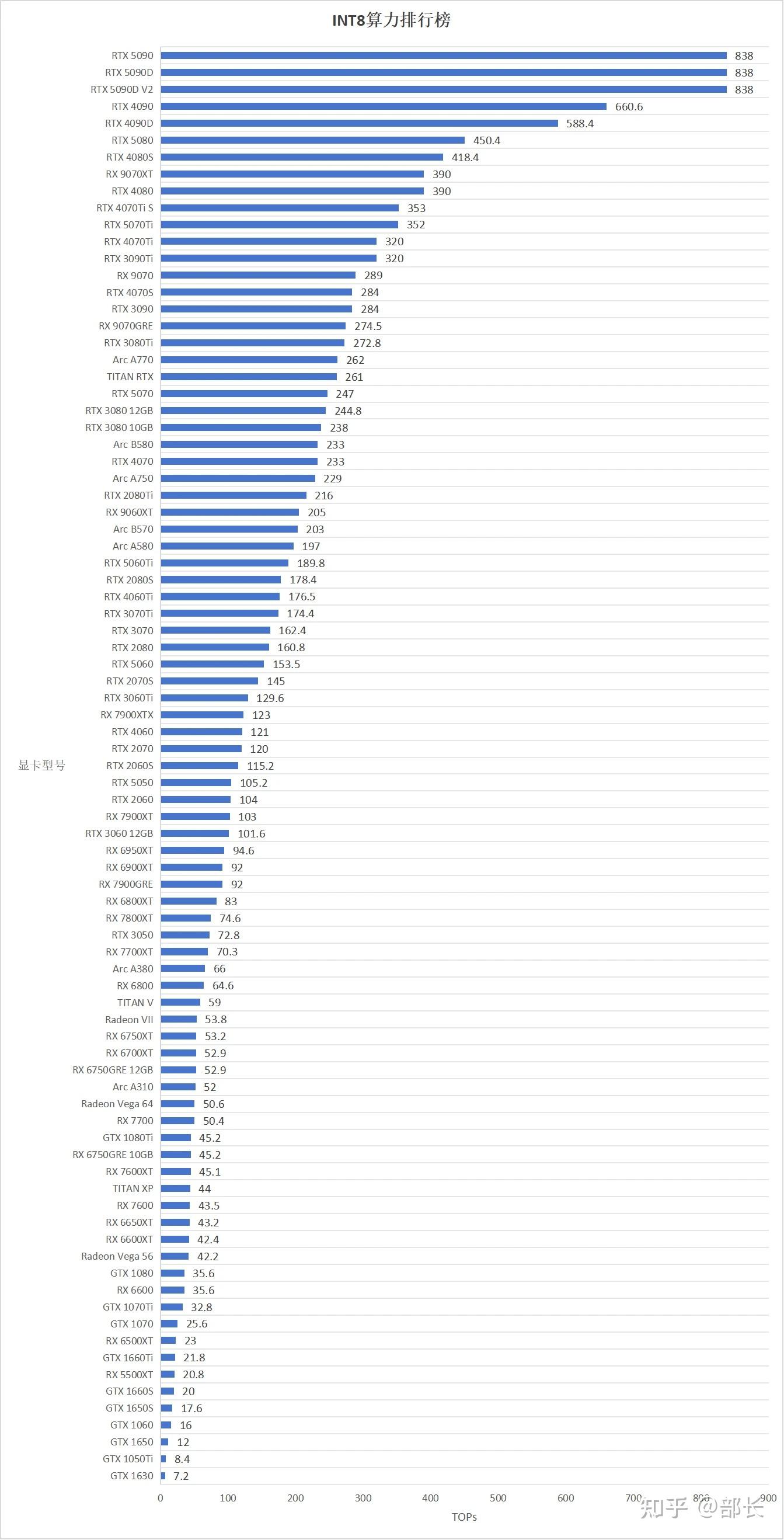
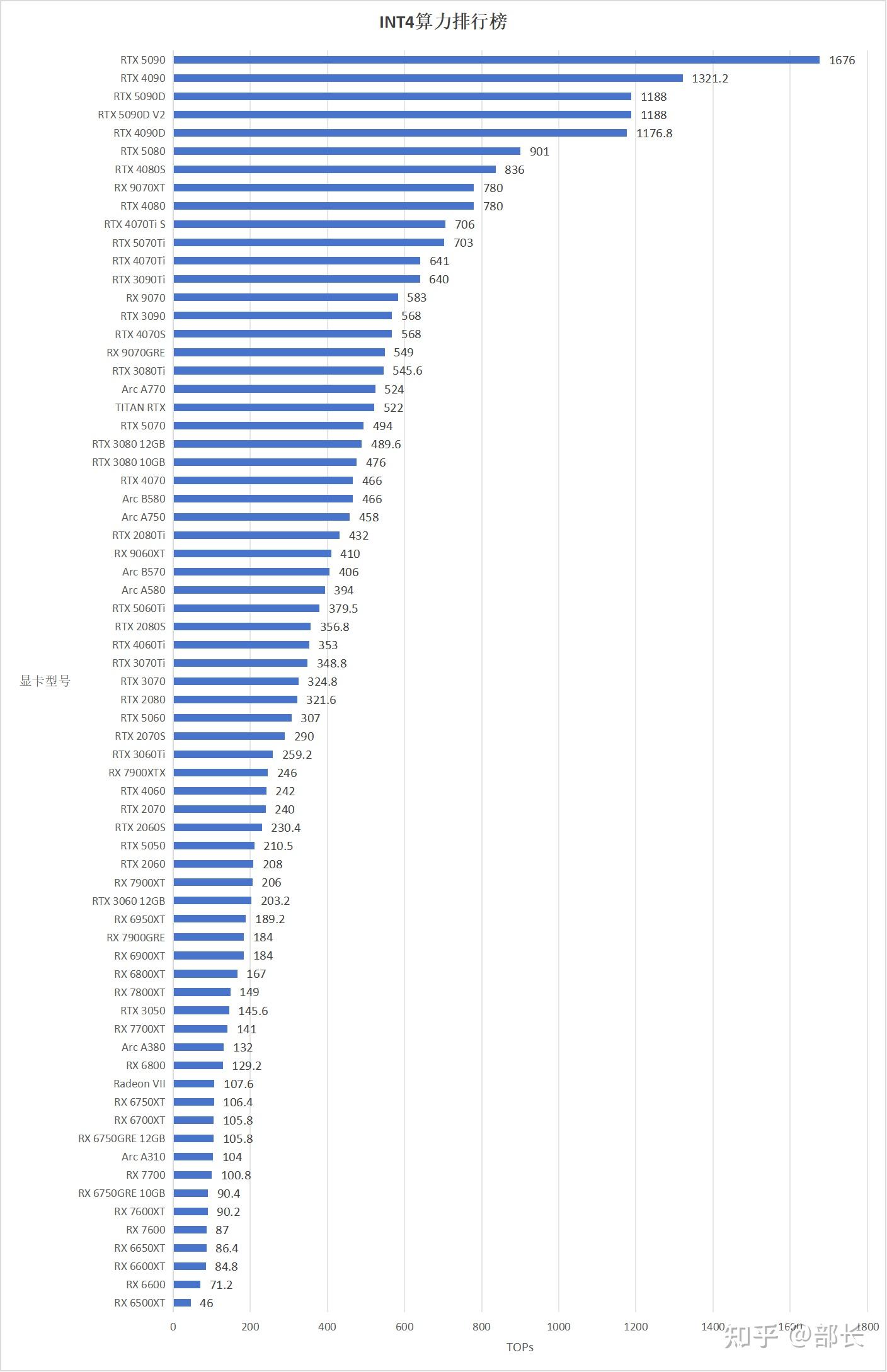
显卡ai算力排行榜(fp16,fp8 fp4,int8,int4) - 知乎
FP8: Efficient model inference with 8-bit floating point numbers ...
int8/int4 模型不存在 · Issue #88 · baichuan-inc/Baichuan-13B · GitHub
有没有考虑支持双卡int8的方案,int4毕竟是有一定的精度损失 · Issue #531 · kvcache-ai ...
FP16、FP32、INT8、混合精度-CSDN博客
服务器测试之GPU基础汇总_fieldiag-CSDN博客